

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- tree
- slidingwindow
- 파이썬기초100제
- two-pointer
- 슬라이딩윈도우
- 생성형AI
- 니트코드
- 리트코드
- 투포인터
- GenerativeAI
- 릿코드
- SQL
- stratascratch
- 파이썬알고리즘
- Microsoft
- 알고리즘
- GenAI
- codeup
- heap
- dfs
- gcp
- LeetCode
- 코드업
- 파이썬
- medium
- nlp
- 자연어처리
- Python
- Python3
- sql코테
- Today
- Total
Tech for good
자연어 언어모델 ‘BERT’ 1강 - 자연어 처리 (NLP) | T아카데미 본문
모든 출처: Sk techx Tacademy (www.youtube.com/watch?v=qlxrXX5uBoU&t=1s)
강의 목표
- 자연어 처리의 종류와, 자연어 처리가 현업에서 적용된 예제를 소개한다.
- BERT가 탄생하게 된 과정과, BERT에 적용된 메커니즘을 살펴본다.
- BERT를 이용한 다양한 자연어 처리 실험 결과들을 소개한다.
- Open source로 공개된 BERT 코드를 이용해 한국어 BERT를 학습해보고, 다양한 자연어 처리 task를 직접 실습해본다.
목차
- 1. 자연어 처리(Natural Language Processing, NLP)
- 1.1. 자연어란?
- 1.2. 자연어 처리 기술
- 1.2.1. 자연어 처리 접근법
- 1.2.2. 자연어 처리 단계
- 1.2.3. 다양한 자연어 처리 Applications
- 1.2.4. 자연어 특징 추출과 분류
- 1.3. Word embedding
- 1.3.1. Word2Vec
- 1.3.2. FastText
- 1.3.3. Word embedding의 활용 및 한계점
1. 자연어 처리
- 자연어의 개념과, 자연어를 수학적으로 표현하는 방법에 대해 알아본다.
1.1. 자연어란?

인코딩 -> 디코딩
자연언어
: 일반 사회에서 자연히 발생하여 쓰이는 언어
- 자연언어: 한국어, 영어, 일본어
- 인공언어: 프로그래밍 언어, 에스페란토어
자연어 처리
: 컴퓨터를 이용하여 인간 언어의 이해, 생성 및 분석을 다루는 인공 지능 기술

: 즉, '자연어를 컴퓨터가 해독하고 그 의미를 이해하는 기술'
1.2. 자연어 처리 기술
1.2.1. 자연어 처리 접근법
- Symbolic approach(규칙/지식 기반 접근법)
- Statistical approach(확률/통계 기반 접근법)
- TF-IDF를 이용한 키워드 추출 (참고: http://dianakang.tistory.com/4)
- TF(Term Frequency): 단어가 문서에 등장한 개수 -> TF가 높을수록 중요한 단어
- DF(Document Frequency): 해당 단어가 등장한 문서의 개수 -> DF가 높을수록 중요하지 않은 단어
- Statistical approach를 딥러닝 기술에 적용하는 연구가 많아지고 있음.
1.2.2. 자연어 처리 단계
- 전처리
- 개행문자 제거
- 특수문자 제거
- 공백 제거
- 중복 표현 제어(ㅋㅋㅋㅋㅋ, ㅠㅠㅠㅠㅠ, ...)
- 이메일, 링크 제거
- 제목 제거
- 불용어(의미가 없는 용어) 제거
- 조사 제거
- 띄어쓰기, 문장분리 보정
- 사전 구축
- Tokenizing
- 자연어를 어떤 단위로 살펴볼 것인가
- 어절 tokenizing
- 형태소 tokenizing
- n-gram tokenizing
- WordPiece tokenizing
- Lexical analysis
- 어휘 분석
- 형태소 분석
- 개체명 인식
- 상호 참조
- Syntactic analysis
- 구문 분석
- Semantic analysis
- 의미 분석
1.2.3. 다양한 자연어 처리 Applications
- 문서 분류 --- (카테고리화)
- 문법, 오타 교정
- 정보 추출
- 음성 인식결과 보정
- 음성 합성 텍스트 보정
- 정보 검색
- 요약문 생성
- 기계 번역
- 질의 응답
- 기계 독해
- 챗봇
- 형태소 분석
- 개체명 분석
- 구문 분석
- 감성 분석
- 관계 추출
- 의도 파악

-> 대부분의 자연어 처리 문제는 '분류' 문제
-> '분류'를 위해선 데이터를 수학적으로 표현
-> 먼저, 분류 대상의 특징(Feature)을 파악 --- (Feature extraction)
-> 분류 대상의 특징 (Feature)을 기준으로, 분류 대상을 그래프 위에 표현 가능
-> 분류 대상들의 경계를 수학적으로 나눌 수 있음 (Classification)
-> 새로운 데이터 역시 특징을 기준으로 그래프에 표현하면, 어떤 그룹과 유사한지 파악 가능
1.2.4. 자연어 특징 추출과 분류
- 먼저, 분류 대상의 특징(Feature)을 파악 ---(Feature extraction)
- 분류 대상의 특징(Feature)을 기준으로, 분류 대상을 그래프 위에 표현 가능
- 분류 대상들의 경계를 수학적으로 나눌 수 있음 --- (Classification)
- 새로운 데이터 역시 특징을 기준으로 그래프에 표현하면, 어떤 그룹과 유사한지 파악 가능
- 과거에는 사람이 직접 특징(Feature)을 파악해서 분류
- 실제 복잡한 문제들에선 분류 대상의 특징을 사람이 파악하기 어려울 수 있음
- 이러한 특징을 컴퓨터가 스스로 찾고(Feature extraction), 스스로 분류(Classification)하는 것이 '기계학습'의 핵심 기술
1.3. Word Embedding
1.3.1. Word2Vec

자연어에서 특징을 추출하여 좌표 평면 위에 표현하는 가장 대표적인 방법은 '원-핫 인코딩'이다.
'세상 모든 사람' 이라는 위의 예시를 어절 단위로 분리하면, '세상', '모든', '사람'이라는 세 개의 vocabulary를 가진다.
이러한 vocabulary를 [1,0,0] 같은 3차원 벡터 평면 위에 '원-핫 인코딩' 방식으로 표현하는 것을 'Sparse representation' 이라고 한다. 가장 단순한 표현 방법이다. 이제 자연어를 좌표 평면 위에 나열하는 것은 성공했다!
하지만 이러한 방식에는 문제가 있다. n개의 단어가 입력으로 들어오게 되면, 벡터사이즈도 그만큼 무한으로 늘어나는 것이다. 또한 이렇게 좌표 평면 위에 나열 되어 있는 벡터 표현을 봤을 때 의미 파악이 쉽지 않다.

이러한 단점들을 보완하기 위해 등장한 알고리즘이 Word2Vec이다. 이 알고리즘은 자연어를 의미 공간에 임베딩하는 알고리즘 중의 하나이다. 이 알고리즘의 핵심은 단어의 주변 단어를 통해 그 의미를 파악하는 것이다.

문장의 단어를 원핫벡터로 치환해 인풋으로 주고 아웃풋인 주변 단어의 원핫 벡터를 구하는 것이 핵심이다.

-> Dense representation을 이용한 Word2Vec 모델은 주변 단어를 이용하여 학습이 이루어지기 때문에 비지도학습으로도 단어 임베딩을 할 수 있다.


- Word embedding 성능 검증 방법
- WordSim353 <- Similarity(유사도) 비교
- Semantic/ Syntactic analogy - 덧셈/뺄셈을 이용해 임베딩 공간을 확인하는 기법
- Semantic analogy - 의미관계 파악
- Syntactic analogy - 문법구조 파악

- Word embedding - Word2Vec의 단점
- Our of vocabulary(OOV)에서 적용 불가능-> 즉, 학습에 사용되지 않은 단어가 입력으로 들어오게 되면, 그 단어에 대해서는 벡터공간을 추론할 수 없는 단점이 있음.
1.3.2. FastText

'용언이나 subword들을 활용하여 단어 임베딩을 해보면 어떨까?'라는 의문에서 만들어진 FastText.
-
- 주변 단어들을 이용하여 학습이 이루어지는 것은 Word2Vec과 같음
- 대신, 원래 단어를 n-gram으로 분리하여 학습함.FastText

만약 위의 예시에서 "assume"이 인풋으로 들어오면, Word2Vec의 경우 vocabulary("assumption")가 완전 다르기 때문에 아예 벡터를 추론할 수 없다. 반면, FastText를 이용해 "assume"의 n-gram을 확인해보면 피처(feature)가 "assumption"을 학습할 때, 다 학습이 되었던 피처이므로 이들을 다 합산하여 assume 벡터를 얻어낼 수 있다. 결과적으로 OOV가 입력으로 들어오더라도, 입력 단어의 n-gram으로 벡터를 만들어 낼 수 있다.


Oranges라는 OOV가 들어온 경우를 살펴보면, Orange가 가지고 있는 n-gram과 굉장히 유사하다는 것을 확인할 수 있다.

오탈자가 있는 OOV에 관해서도 위와 같은 워드벡터를 얻어 낼 수 있다.
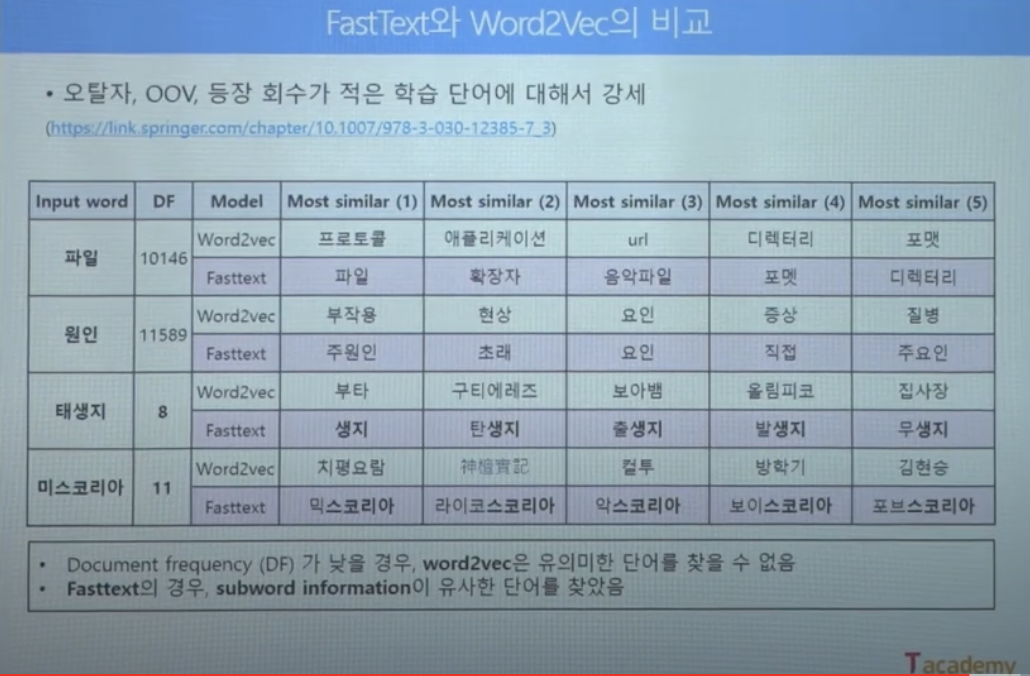

1.3.3. Word embedding의 활용 및 한계점


- Word embedding의 한계점
: Word2Vec이나 FastText 같은 Word embedding 기법은 원래 단어의 주변 단어를 관찰함으로써 학습이 이루어진다.
그래서 만약 다의어, 동형어 같은 단어들이 입력으로 들어가게 되면, 이들을 분리해서 학습하는 것이 불가능해진다.
즉, 주변 단어를 통해 학습이 이루어지기 때문에 '문맥'을 고려할 수 없다는 단점이 있다.
'IT > Data Science' 카테고리의 다른 글
| [Reading a thesis every week] Continual learning for named entity recognition(2021) (0) | 2021.05.30 |
|---|---|
| 자연어 언어모델 ‘BERT’ 2강 - 언어 모델(Language Model) | T아카데미 (0) | 2021.04.19 |
| 빅데이터 분석기사 개념정리 - 수제비 2021 빅데이터분석기사 필기 최종 모의고사 3회 (0) | 2021.04.16 |
| 빅데이터 분석기사 개념정리 - 수제비 2021 빅데이터분석기사 필기 최종 모의고사 2회 (0) | 2021.04.15 |
| 빅데이터 분석기사 개념정리 - 수제비 2021 빅데이터분석기사 필기 최종 모의고사 1회 (0) | 2021.04.15 |

