

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- heap
- GenAI
- stratascratch
- 자연어처리
- Python3
- Microsoft
- dfs
- codeup
- 구글퀵랩
- 슬라이딩윈도우
- slidingwindow
- LeetCode
- SQL
- 파이썬기초100제
- GenerativeAI
- 릿코드
- two-pointer
- sql코테
- 리트코드
- medium
- 파이썬알고리즘
- 파이썬
- nlp
- 알고리즘
- 니트코드
- Python
- 투포인터
- 생성형AI
- 코드업
- gcp
- Today
- Total
Tech for good
[딥러닝을 이용한 자연어 처리 입문] 6. 토픽 모델링(Topic Modeling)- 2) 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) 본문
[딥러닝을 이용한 자연어 처리 입문] 6. 토픽 모델링(Topic Modeling)- 2) 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
Diana Kang 2021. 10. 14. 11:44목차
6. 토픽 모델링(Topic Modeling)
6.2. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)
6.2.1. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) 개요
6.2.2. LDA의 가정
6.2.3. LDA의 수행하기
6.2.4. 잠재 디리클레 할당(LDA)과 잠재 의미 분석(LSA)의 차이
6.2.5. 실습을 통한 이해
(1) 정수 인코딩과 단어 집합 만들기
(2) LDA 모델 훈련시키기
(3) LDA 시각화하기
(4) 문서 별 토픽 분포 보기
6. 토픽 모델링(Topic Modeling)
6.2. 잠재 디리클레 할당(Latent Dirichlet Allocation; LDA)
토픽 모델링은 문서의 집합에서 토픽을 찾아내는 프로세스를 말한다. 이는 검색 엔진, 고객 민원 시스템 등과 같이 문서의 주제를 알아내는 일이 중요한 곳에서 사용된다. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)은 토픽 모델링의 대표적인 알고리즘이다.
LDA 문서들은 토픽들의 혼합으로 구성되어져 있으며, 토픽들은 확률 분포에 기반하여 단어들을 생성한다고 가정한다. 데이터가 주어지면, LDA는 문서가 생성되던 과정을 역추적한다.
참고링크 : https://lettier.com/projects/lda-topic-modeling/
위의 사이트는 코드 작성 없이 입력한 문서들로부터 DTM을 만들고 LDA를 수행한 결과를 보여주는 웹 사이트이다.
6.2.1. 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) 개요
우선 LDA의 내부 메커니즘에 대해서 이해하기 전에, LDA를 일종의 블랙 박스로 보고 LDA에 문서 집합을 입력하면, 어떤 결과를 보여주는지 간소화 된 예를 들어 보겠다. 아래와 같은 3개의 문서가 있다고 해보자. 지금의 예제는 간단해서 눈으로도 토픽 모델링을 할 수 있을 것 같지만, 실제 수십만개 이상의 문서가 있는 경우는 직접 토픽을 찾아내는 것이 어렵기 때문에 LDA의 도움이 필요하다.
문서1 : 저는 사과랑 바나나를 먹어요
문서2 : 우리는 귀여운 강아지가 좋아요
문서3 : 저의 깜찍하고 귀여운 강아지가 바나나를 먹어요
LDA를 수행할 때 문서 집합에서 토픽이 몇 개가 존재할지 가정하는 것은 사용자가 해야 할 일이다. 여기서는 LDA에 2개의 토픽을 찾으라고 요청하겠다. 토픽의 개수를 의미하는 변수를 k라고 하였을 때, k를 2로 한다는 의미이다. k의 값을 잘못 선택하면 원치않는 이상한 결과가 나올 수 있다. 이렇게 모델의 성능에 영향을 주는 사용자가 직접 선택하는 매개변수를 머신러닝 용어로 하이퍼파라미터라고 합니다. 이러한 하이퍼파라미터의 선택은 여러 실험을 통해 얻은 값일 수도 있고, 우선 시도해보는 값일 수도 있다.
LDA가 위의 세 문서로부터 2개의 토픽을 찾은 결과는 아래와 같다. 여기서는 LDA 입력 전에 주어와 불필요한 조사 등을 제거하는 전처리 과정은 거쳤다고 가정한다. 즉, 전처리 과정을 거친 DTM이 LDA의 입력이 되었다고 가정한다.
LDA는 각 문서의 토픽 분포와 각 토픽 내의 단어 분포를 추정한다.
<각 문서의 토픽 분포>
문서1 : 토픽 A 100%
문서2 : 토픽 B 100%
문서3 : 토픽 B 60%, 토픽 A 40%
<각 토픽의 단어 분포>
토픽A : 사과 20%, 바나나 40%, 먹어요 40%, 귀여운 0%, 강아지 0%, 깜찍하고 0%, 좋아요 0%
토픽B : 사과 0%, 바나나 0%, 먹어요 0%, 귀여운 33%, 강아지 33%, 깜찍하고 16%, 좋아요 16%
LDA는토픽의 제목을 정해주지 않지만, 이 시점에서 알고리즘의 사용자는 위 결과로부터 두 토픽이 각각 과일에 대한 토픽과 강아지에 대한 토픽이라고 판단해볼 수 있다. 그럼 이제 LDA에 대해서 알아보자. 실제로 LDA는 아래의 설명보다 훨씬 더 복잡하지만, 여기서는 수학적인 수식은 배제하고 개념적 이해에 초점을 둔다.
6.2.2. LDA의 가정
LDA는 문서의 집합으로부터 어떤 토픽이 존재하는지를 알아내기 위한 알고리즘이다. LDA는 앞서 배운 빈도수 기반의 표현 방법인 BoW의 행렬 DTM 또는 TF-IDF 행렬을 입력으로 하는데, 이로부터 알 수 있는 사실은 LDA는 단어의 순서는 신경쓰지 않겠다는 것이다.
LDA는 문서들로부터 토픽을 뽑아내기 위해서 이러한 가정을 염두해두고 있다. 모든 문서 하나, 하나가 작성될 때 그 문서의 작성자는 이러한 생각을 한다. '나는 이 문서를 작성하기 위해서 이런 주제들을 넣을거고, 이런 주제들을 위해서는 이런 단어들을 넣을 거야.' 즉, 각각의 문서는 다음과 같은 과정을 거쳐서 작성되었다고 가정한다.
1) 문서에 사용할 단어의 개수 N을 정한다.
- Ex) 5개의 단어를 정하였다.
2) 문서에 사용할 토픽의 혼합을 확률 분포에 기반하여 결정한다.
- Ex) 위 예제와 같이 토픽이 2개라고 하였을 때 강아지 토픽을 60%, 과일 토픽을 40%와 같이 선택할 수 있다.
3) 문서에 사용할 각 단어를 (아래와 같이) 정한다.
3-1) 토픽 분포에서 토픽 T를 확률적으로 고른다.
- Ex) 60% 확률로 강아지 토픽을 선택하고, 40% 확률로 과일 토픽을 선택할 수 있다.
3-2) 선택한 토픽 T에서 단어의 출현 확률 분포에 기반해 문서에 사용할 단어를 고른다.
- Ex) 강아지 토픽을 선택하였다면, 33% 확률로 강아지란 단어를 선택할 수 있다. 이제 3)을 반복하면서 문서를 완성한다.
이러한 과정을 통해 문서가 작성되었다는 가정 하에 LDA는 토픽을 뽑아내기 위하여 위 과정을 역으로 추적하는 역공학(reverse engneering)을 수행한다.
6.2.3. LDA의 수행하기
이제 LDA의 수행 과정을 정리해보겠다.
1) 사용자는 알고리즘에게 토픽의 개수 k를 알려준다.
앞서 말하였듯이 LDA에게 토픽의 개수를 알려주는 역할은 사용자의 역할이다. LDA는 토픽의 개수 k를 입력받으면, k개의 토픽이 M개의 전체 문서에 걸쳐 분포되어 있다고 가정한다.
2) 모든 단어를 k개 중 하나의 토픽에 할당합니다.
이제 LDA는 모든 문서의 모든 단어에 대해서 k개 중 하나의 토픽을 랜덤으로 할당한다. 이 작업이 끝나면 각 문서는 토픽을 가지며, 토픽은 단어 분포를 가지는 상태이다. 물론 랜덤으로 할당하였기 때문에 사실 이 결과는 전부 틀린 상태이. 만약 한 단어가 한 문서에서 2회 이상 등장하였다면, 각 단어는 서로 다른 토픽에 할당되었을 수도 있다.
3) 이제 모든 문서의 모든 단어에 대해서 아래의 사항을 반복 진행한다. (iterative)
3-1) 어떤 문서의 각 단어 w는 자신은 잘못된 토픽에 할당되어져 있지만, 다른 단어들은 전부 올바른 토픽에 할당되어져 있는 상태라고 가정한다. 이에 따라 단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당된다.
- p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
- p(word w | topic t) : 각 토픽들 t에서 해당 단어 w의 분포
이를 반복하면, 모든 할당이 완료된 수렴 상태가 된다. 두 가지 기준이 어떤 의미인지 예를 들어보겠다. 설명의 편의를 위해서 두 개의 문서라는 새로운 예를 사용한다.

위의 그림은 두 개의 문서 doc1과 doc2를 보여준다. 여기서는 doc1의 세번째 단어 apple의 토픽을 결정하고자 한다.

우선 첫번째로 사용하는 기준은 문서 doc1의 단어들이 어떤 토픽에 해당하는지를 본다. doc1의 모든 단어들은 토픽 A와 토픽 B에 50 대 50의 비율로 할당되어져 있으므로, 이 기준에 따르면 단어 apple은 토픽 A 또는 토픽 B 둘 중 어디에도 속할 가능성이 있다.

두번째 기준은 단어 apple이 전체 문서에서 어떤 토픽에 할당되어져 있는지를 본다. 이 기준에 따르면 단어 apple은 토픽 B에 할당될 가능성이 높다. 이러한 두 가지 기준을 참고하여 LDA는 doc1의 apple을 어떤 토픽에 할당할지 결정한다.
6.2.4. 잠재 디리클레 할당(LDA)와 잠재 의미 분석(LSA)의 차이
- 잠재 의미 분석(LSA): DTM을 차원 축소하여 축소 차원에서 근접 단어들을 토픽으로 묶는다.
- 잠재 디리클레 할당(LDA): 단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합확률로 추정하여 토픽을 추출한다.
6.2.5. 실습을 통한 이해
이제 LDA를 실습을 통해 직접 진행해보록 하자. LSA 챕터에서는 사이킷런(sklearn)을 사용하였지만, 이번 챕터에서는 gensim을 사용하므로 앞서 챕터와 실습 과정이 확연히 다르다.
1) 정수 인코딩과 단어 집합 만들기
바로 이전 챕터인 LSA 챕터에서 사용하였던 Twenty Newsgroups이라고 불리는 20개의 다른 주제를 가진 뉴스 데이터를 다시 사용한다. 전처리 과정은 이전 챕터와 중복되므로 생략한다. 동일한 전처리 과정을 거친 후에 tokenized_doc으로 저장한 상태라고 해보자. 그럼 이제 훈련용 뉴스를 5개만 출력해보겠다.
tokenized_doc[:5]0 [well, sure, about, story, seem, biased, what,...
1 [yeah, expect, people, read, actually, accept,...
2 [although, realize, that, principle, your, str...
3 [notwithstanding, legitimate, fuss, about, thi...
4 [well, will, have, change, scoring, playoff, p...
Name: clean_doc, dtype: object
이제 각 단어에 정수 인코딩을 하는 동시에, 각 뉴스에서의 단어의 빈도수를 기록해보겠다. 여기서는 각 단어를 (word_id, word_frequency)의 형태로 바꾸고자 한다. word_id는 단어가 정수 인코딩된 값이고, word_frequency는 해당 뉴스에서의 해당 단어의 빈도수를 의미한다. 이는 gensim의 corpora.Dictionary()를 사용하여 손쉽게 구할 수 있다. 전체 뉴스에 대해서 정수 인코딩을 수행하고, 두번째 뉴스를 출력해보자.
from gensim import corpora
dictionary = corpora.Dictionary(tokenized_doc)
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]
print(corpus[1]) # 수행된 결과에서 두번째 뉴스 출력. 첫번째 문서의 인덱스는 0[(52, 1), (55, 1), (56, 1), (57, 1), (58, 1), (59, 1), (60, 1), (61, 1), (62, 1), (63, 1), (64, 1), (65, 1), (66, 2), (67, 1), (68, 1), (69, 1), (70, 1), (71, 2), (72, 1), (73, 1), (74, 1), (75, 1), (76, 1), (77, 1), (78, 2), (79, 1), (80, 1), (81, 1), (82, 1), (83, 1), (84, 1), (85, 2), (86, 1), (87, 1), (88, 1), (89, 1)]
두번째 뉴스의 출력 결과를 보자. 위의 출력 결과 중에서 (66, 2)는 정수 인코딩이 66으로 할당된 단어가 두번째 뉴스에서는 두 번 등장하였음을 의미한다. 그럼 이제 66이라는 값을 가지는 단어가 정수 인코딩이 되기 전에는 어떤 단어였는지 확인하여보자. 이는 dictionary[]에 기존 단어가 무엇인지 알고자하는 정수값을 입력하여 확인할 수 있다.
print(dictionary[66])faith
기존에는 단어 'faith'이었음을 알 수 있다. 총 학습된 단어의 개수를 확인해보겠다. 이는 dictionary의 길이를 확인하면 된다.
len(dictionary)65284총 65,284개의 단어가 학습되었다. 이제 LDA 모델을 훈련시켜보겠다.
2) LDA 모델 훈련시키기
기존의 뉴스 데이터가 총 20개의 카테고리를 가지고 있었으므로 토픽의 개수를 20으로 하여 LDA 모델을 학습시켜보도록 한다.
import gensim
NUM_TOPICS = 20 #20개의 토픽, k=20
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=dictionary, passes=15)
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)(0, '0.015*"drive" + 0.014*"thanks" + 0.012*"card" + 0.012*"system"')
(1, '0.009*"back" + 0.009*"like" + 0.009*"time" + 0.008*"went"')
(2, '0.012*"colorado" + 0.010*"david" + 0.006*"decenso" + 0.005*"tyre"')
(3, '0.020*"number" + 0.018*"wire" + 0.013*"bits" + 0.013*"filename"')
(4, '0.038*"space" + 0.013*"nasa" + 0.011*"research" + 0.010*"medical"')
(5, '0.014*"price" + 0.010*"sale" + 0.009*"good" + 0.008*"shipping"')
(6, '0.012*"available" + 0.009*"file" + 0.009*"information" + 0.008*"version"')
(7, '0.021*"would" + 0.013*"think" + 0.012*"people" + 0.011*"like"')
(8, '0.035*"window" + 0.021*"display" + 0.017*"widget" + 0.013*"application"')
(9, '0.012*"people" + 0.010*"jesus" + 0.007*"armenian" + 0.007*"israel"')
(10, '0.008*"government" + 0.007*"system" + 0.006*"public" + 0.006*"encryption"')
(11, '0.013*"germany" + 0.008*"sweden" + 0.008*"switzerland" + 0.007*"gaza"')
(12, '0.020*"game" + 0.018*"team" + 0.015*"games" + 0.013*"play"')
(13, '0.024*"apple" + 0.014*"water" + 0.013*"ground" + 0.011*"cable"')
(14, '0.011*"evidence" + 0.010*"believe" + 0.010*"truth" + 0.010*"church"')
(15, '0.016*"president" + 0.010*"states" + 0.007*"united" + 0.007*"year"')
(16, '0.047*"file" + 0.035*"output" + 0.033*"entry" + 0.021*"program"')
(17, '0.008*"dept" + 0.008*"devils" + 0.007*"caps" + 0.007*"john"')
(18, '0.011*"year" + 0.009*"last" + 0.007*"first" + 0.006*"runs"')
(19, '0.013*"outlets" + 0.013*"norton" + 0.012*"quantum" + 0.008*"neck"')
각 단어 앞에 붙은 수치는 단어의 해당 토픽에 대한 기여도를 보여준다. 또한 맨 앞에 있는 토픽 번호는 0부터 시작하므로 총 20개의 토픽은 0부터 19까지의 번호가 할당되어져 있다. passes는 알고리즘의 동작 횟수를 말하는데, 알고리즘이 결정하는 토픽의 값이 적절히 수렴할 수 있도록 충분히 적당한 횟수를 정해주면 된다. 여기서는 총 15회를 수행하였다. 여기서는 num_words=4로 총 4개의 단어만 출력하도록 하였다. 만약 10개의 단어를 출력하고 싶다면 아래의 코드를 수행하면 된다.
print(ldamodel.print_topics())
3) LDA 시각화 하기
LDA 시각화를 위해서는 pyLDAvis의 설치가 필요하다. 윈도우의 명령 프롬프트나 MAC/UNIX의 터미널에서 아래의 명령을 수행하여 pyLDAvis를 설치하시기 바란다.
pip install pyLDAvis
설치가 완료되면 LDA 시각화 실습을 진행한다.
import pyLDAvis
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(ldamodel, corpus, dictionary)
pyLDAvis.display(vis)
* gensim 라이브러리
: 자연어를 벡터로 변환하는데 필요한 대부분의 편의기능을 제공하고 있는 라이브러리 (Word2vec도 포함)
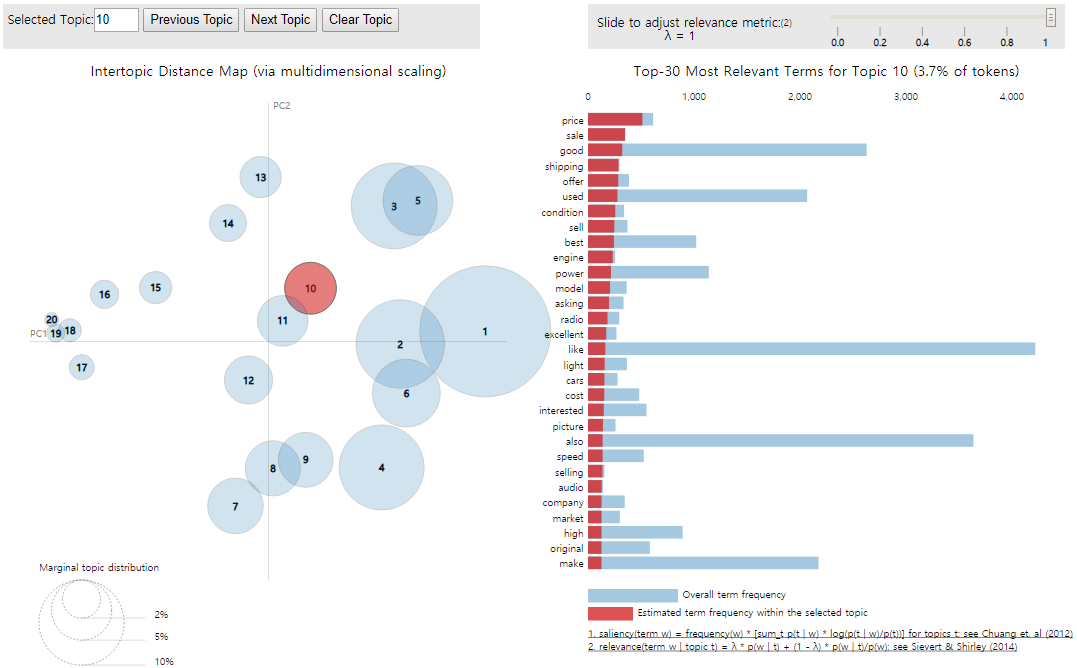
좌측의 원들은 각각의 20개의 토픽을 나타낸다. 각 원과의 거리는 각 토픽들이 서로 얼마나 다른지를 보여준다. 만약 두 개의 원이 겹친다면, 이 두 개의 토픽은 유사한 토픽이라는 의미이다. 위의 그림에서는 10번 토픽을 클릭하였고, 이에 따라 우측에는 10번 토픽에 대한 정보가 나타난다. 한 가지 주의할 점은 LDA 모델의 출력 결과에서는 토픽 번호가 0부터 할당되어 0~19의 숫자가 사용된 것과는 달리 위의 LDA 시각화에서는 토픽의 번호가 1부터 시작하므로 각 토픽 번호는 이제 +1이 된 값인 1~20까지의 값을 가진다.
4) 문서 별 토픽 분포 보기
위에서 토픽 별 단어 분포는 확인하였으나, 아직 문서 별 토픽 분포에 대해서는 확인하지 못하였다. 우선 문서 별 토픽 분포를 확인하는 방법을 보겠다. 각 문서의 토픽 분포는 이미 훈련된 LDA 모델인 ldamodel[]에 전체 데이터가 정수 인코딩 된 결과를 넣은 후에 확인이 가능하다. 여기서는 책의 지면의 한계로 상위 5개의 문서에 대해서만 토픽 분포를 확인해보겠다.
for i, topic_list in enumerate(ldamodel[corpus]):
if i==5:
break
print(i,'번째 문서의 topic 비율은',topic_list)0 번째 문서의 topic 비율은 [(7, 0.3050222), (9, 0.5070568), (11, 0.1319604), (18, 0.042834017)]
1 번째 문서의 topic 비율은 [(0, 0.031606797), (7, 0.7529218), (13, 0.02924682), (14, 0.12861845), (17, 0.037851967)]
2 번째 문서의 topic 비율은 [(7, 0.52241164), (9, 0.36602455), (16, 0.09760969)]
3 번째 문서의 topic 비율은 [(1, 0.16926806), (5, 0.04912094), (6, 0.04034211), (7, 0.11710636), (10, 0.5854137), (15, 0.02776434)]
4 번째 문서의 topic 비율은 [(7, 0.42152268), (12, 0.21917087), (17, 0.32781804)]
위의 출력 결과에서 (숫자, 확률)은 각각 토픽 번호와 해당 토픽이 해당 문서에서 차지하는 분포도를 의미한다. 예를 들어 0번째 문서의 토픽 비율에서 (7, 0.3050222)은 7번 토픽이 30%의 분포도를 가지는 것을 의미한다. 위의 코드를 응용하여 좀 더 깔끔한 형태인 데이터프레임 형식으로 출력해보겠다.
# 각 문서에 대한 토픽 분포를 출력하는 코드(즉, 특정 문서에 대한 모델의 토픽 예측 코드)
def make_topictable_per_doc(ldamodel, corpus):
topic_table = pd.DataFrame()
# 몇 번째 문서인지를 의미하는 문서 번호와 해당 문서의 토픽 비중을 한 줄씩 꺼내온다.
for i, topic_list in enumerate(ldamodel[corpus]):
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x: (x[1]), reverse=True)
# 각 문서에 대해서 비중이 높은 토픽순으로 토픽을 정렬한다.
# EX) 정렬 전 0번 문서 : (2번 토픽, 48.5%), (8번 토픽, 25%), (10번 토픽, 5%), (12번 토픽, 21.5%),
# Ex) 정렬 후 0번 문서 : (2번 토픽, 48.5%), (8번 토픽, 25%), (12번 토픽, 21.5%), (10번 토픽, 5%)
# 48 > 25 > 21 > 5 순으로 정렬이 된 것.
# 모든 문서에 대해서 각각 아래를 수행
for j, (topic_num, prop_topic) in enumerate(doc): # 몇 번 토픽인지와 비중을 나눠서 저장한다.
if j == 0: # 정렬을 한 상태이므로 가장 앞에 있는 것이 가장 비중이 높은 토픽
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]), ignore_index=True)
# 가장 비중이 높은 토픽과, 가장 비중이 높은 토픽의 비중과, 전체 토픽의 비중을 저장한다.
else:
break
return(topic_table)topictable = make_topictable_per_doc(ldamodel, corpus)
topictable = topictable.reset_index() # 문서 번호을 의미하는 열(column)로 사용하기 위해서 인덱스 열을 하나 더 만든다.
topictable.columns = ['문서 번호', '가장 비중이 높은 토픽', '가장 높은 토픽의 비중', '각 토픽의 비중']
topictable[:10]
+ 한 문서는 하나의 토픽을 가지는 것이 아니라 여러 개의 토픽을 가질 수 있다. 위에 '가장 비중이 높은 토픽'을 별도의 열로 출력한 이유 또한 이러한 이유 때문이다.
+ gensim의 lda는 훈련에 사용된 corpus가 아닌 새로운 document에 대해서도 토픽 모델링의 결과를 얻는 것도 지원한다. 아래의 코드는 훈련에 사용하지 않은 임의의 새로운 document를 lda 모델에 입력으로 사용하기 위해 아주 간단한 전처리만 거치고 lda 모델의 입력으로 사용하여 결과를 출력해보는 코드이다.
def doc_to_bow(doc): # 토큰화 후에 bow로 바꾸는 코드
token = doc.split() # 불용어 제거 소문자화 등의 전처리는 여기서는 그냥 안 하겠습니다.
bow = dictionary.doc2bow(token)
return bow
result=ldamodel[(doc_to_bow('new document to be classified by trained model'))]
print(result)[(0, 0.40991104), (1, 0.010009108), (2, 0.010009108), (3, 0.010009108), (4, 0.010009108), (5, 0.010009108), (6, 0.010009109), (7, 0.010009108), (8, 0.010009108), (9, 0.010009108), (10, 0.010009108), (11, 0.010009108), (12, 0.19731404), (13, 0.010009108), (14, 0.22262006), (15, 0.010009108), (16, 0.010009108), (17, 0.01000911), (18, 0.010009108), (19, 0.010009108)]
+ 모델에 없는 단어가 섞여있어도 토픽 모델링을 수행할 수 있다. 하지만 모델에 없는 단어는 특정 토픽에 속할 가능성이 높다 라는 의미있는 정보를 줄 수는 없다. 이는 아래의 코드(모델에 있는 단어와 모델에 없는 단어를 섞어서 수행)를 수행하면 알 수 있는데, 결국 모델에 있는 단어 위주로 판단하는 결과를 보인다.
def doc_to_bow(doc): # bow로 바꾸는 코드
token = doc.split()
bow = dictionary.doc2bow(token)
return bow
result=ldamodel[(doc_to_bow('oov unk'))]
print(result)[(0, 0.05), (1, 0.05), (2, 0.05), (3, 0.05), (4, 0.05), (5, 0.05), (6, 0.05), (7, 0.05), (8, 0.05), (9, 0.05), (10, 0.05), (11, 0.05), (12, 0.05), (13, 0.05), (14, 0.05), (15, 0.05), (16, 0.05), (17, 0.05), (18, 0.05), (19, 0.05)]20개의 토픽이 있으니까 1이라는 숫자를 20으로 나눈 0.05로 전부 균등한 토픽으로 보는 것이다. 결국 모델에 없는 단어들은 어떤 토픽에 속할 가능성이 높다라는 의미있는 정보를 주지 못하고 있는 것이다. 위의 출력 결과를 통해 모델에 없는 단어(예측하고 싶은 임의의 문서를 corpus화시켜 수행한 경우)를 수행한 경우, 모델에 있는 단어 위주로만 판단하는 결과를 확인할 수 있다.
+ 실습 해보면 좋을 코드
https://joyhong.tistory.com/138


