
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 자연어처리
- 파이썬
- 파이썬알고리즘
- 파이썬기초100제
- Python
- gcp
- 머신러닝
- 구글퀵랩
- 코드업
- 블레이저
- C#
- 코드업파이썬
- 코드업100제
- attention
- 생성형AI
- GenerativeAI
- Microsoft
- 한빛미디어
- 알고리즘
- 빅데이터
- Blazor
- 파이썬기초
- 데이터분석
- 데이터사이언스
- GenAI
- nlp
- Azure
- codeup
- 클라우드
- DataScience
- Today
- Total
Tech for good
[딥러닝을 이용한 자연어 처리 입문] 5. 벡터의 유사도(Vector Similarity) - 1. 코사인 유사도(Cosine Similarity) 본문
[딥러닝을 이용한 자연어 처리 입문] 5. 벡터의 유사도(Vector Similarity) - 1. 코사인 유사도(Cosine Similarity)
Diana Kang 2021. 10. 20. 08:44목차
5. 벡터의 유사도(Vector Similarity)
5.1. 코사인 유사도(Cosine Similarity)
5.1.1. 코사인 유사도(Cosine Similarity)
5.1.2. 유사도를 이용한 추천 시스템 구현하기
5. 벡터의 유사도(Vector Similarity)
문서의 유사도를 구하는 일은 자연어 처리의 주요 주제 중 하나이다. 사람들이 인식하는 문서의 유사도는 주로 문서들 간에 동일한 단어 또는 비슷한 단어가 얼마나 공통적으로 많이 사용되었는지 의존한다. 기계도 마찬가지이다. 기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있다.
5.1. 코사인 유사도(Cosine Similarity)
BoW나 BoW에 기반한 단어 표현 방법인 DTM, TF-IDF, 또는 뒤에서 배우게 될 워드투벡터(Word2Vec) 등과 같이 단어를 수치화할 수 있는 방법을 이해했다면, 이러한 표현 방법에 대해서 코사인 유사도를 이용하여 문서의 유사도를 구하는 게 가능하다.
5.1.1. 코사인 유사도(Cosine Similarity)
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다. 두 벡터의 방향이 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 된다. 즉, 결국 코사인 유사도는 -1이상 1이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미한다.
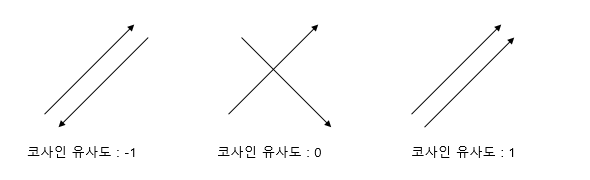
두 벡터 A, B에 대해서 코사인 유사도는 식으로 표현하면 다음과 같다.
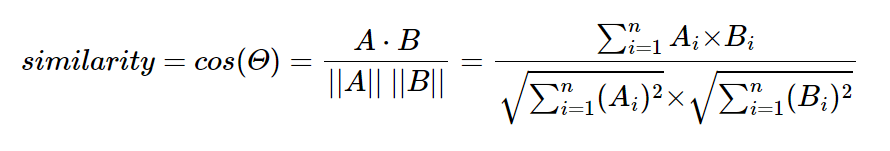
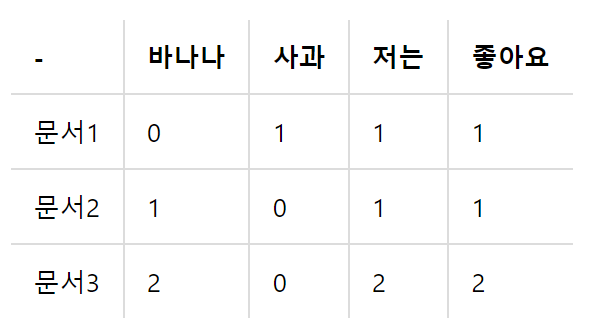
문서 단어 행렬이나 TF-IDF 행렬을 통해서 문서의 유사도를 구하는 경우에는 문서 단어 행렬이나 TF-IDF 행렬이 각각의 특징 벡터 A,B가 된다. 그렇다면 문서 단어 행렬에 대해서 코사인 유사도를 구해보는 간단한 예제를 진행해보겠다.
문서1 : 저는 사과 좋아요
문서2 : 저는 바나나 좋아요
문서3 : 저는 바나나 좋아요 저는 바나나 좋아요
위의 세 문서에 대해서 문서 단어 행렬을 만들면 이와 같다.
파이썬에서 코사인 유사도를 구하는 방법은 여러가지가 있는데 여기서는 Numpy를 이용하여 계산해보겠다.
import numpy as np
from numpy import dot
from numpy.linalg import normdef cos_sim(A, B):
return dot(A, B)/(norm(A)*norm(B))
코사인 유사도를 계산하는 함수를 만들었다.
doc1 = np.array([0,1,1,1])
doc2 = np.array([1,0,1,1])
doc3 = np.array([2,0,2,2])
예를 들었던 문서1, 문서2, 문서3에 대하여 각각 BoW를 만들었다. 이제 각 문서에 대한 코사인 유사도를 계산해보겠다.
print(cos_sim(doc1, doc2)) #문서1과 문서2의 코사인 유사도
print(cos_sim(doc1, doc3)) #문서1과 문서3의 코사인 유사도
print(cos_sim(doc2, doc3)) #문서2과 문서3의 코사인 유사도0.67
0.67
1.00
눈여겨볼만한 점은 문서1과 문서2의 코사인 유사도와 문서1과 문서3의 코사인 유사도가 같다는 점과 문서2와 문서3의 코사인 유사도가 1이 나온다는 것이다. 앞서 1은 두 벡터의 방향이 완전히 동일한 경우이며, 코사인 유사도 관점에서는 유사도의 값이 최대임을 의미한다고 언급하였다.
문서3은 문서2에서 단지 모든 단어의 빈도수가 1씩 증가했을 뿐이다. 다시 말해 한 문서 내의 모든 단어의 빈도수가 동일하게 증가하는 경우에는 기존의 문서와 코사인 유사도의 값이 1이라는 것이다. 이것이 시사하는 점은 무엇일까? 코사인 유사도를 사용하지 않는다고 가정하였을 때, 문서 A에 대해서 모든 문서와의 유사도를 구한다고 가정해보자. 다른 문서들과 문서 B나 거의 동일한 패턴을 가지는 문서임에도 문서 B가 단순히 다른 문서들보다 원문 길이가 긴 문서라는 이유로(단어의 빈도수가 일정하게 더 높아질 때) 다른 문서들보다 유사도가 더 높게 나온다면 이는 우리가 원하는 결과가 아니다. 코사인 유사도는 문서의 길이가 다른 상황에서 비교적 공정한 비교를 할 수 있도록 도와준다.
이는 코사인 유사도는 유사도를 구할 때, 벡터의 크기가 아니라 벡터의 방향(패턴)에 초점을 두기 때문이다. 코사인 유사도가 벡터의 유사도를 구하는 또 다른 방법인 내적과 가지는 차이점이다.
5.1.2. 유사도를 이용한 추천 시스템 구현하기
캐글에서 사용되었던 영화 데이터셋을 가지고 영화 추천 시스템을 만들어보겠다. TF-IDF와 코사인 유사도만으로 영화의 줄거리에 기반해서 영화를 추천하는 추천시스템을 만들 수 있다.
다운로드 링크 : https://www.kaggle.com/rounakbanik/the-movies-dataset
원본 파일은 위 링크에서 movies_metadata.csv 파일을 다운로드 받으면 된다. 해당 데이터는 총 24개의 열을 가진 45,466개의 샘플로 구성된 영화 정보 데이터이다.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similaritydata = pd.read_csv('현재 movies_metadata.csv의 파일 경로', low_memory=False)
data.head(2)
우선 다운로드 받은 훈련 데이터에서 2개의 샘플만 출력하여, 데이터가 어떤 형식을 갖고있는지 확인한다. csv 파일을 읽기 위해서 파이썬 라이브러리인 pandas를 갖고왔는데, pandas는 뒤에서도 pd란 이름으로 계속해서 유용하게 쓰이게 된다.

훈련 데이터는 총 24개의 열을 갖고 있으나, 책의 지면상 일부 생략하였다. 여기서 코사인 유사도에 사용할 데이터는 영화 제목에 해당하는 title 열과 줄거리에 해당하는 overview 열이다. 좋아하는 영화를 입력하면, 해당 영화의 줄거리와 줄거리가 유사한 영화를 찾아서 추천하는 시스템을 만들 것이다.
data = data.head(20000)
만약 훈련 데이터의 양을 줄이고 학습을 진행하고자 한다면, 이와 같이 데이터를 줄여서 재저장할 수 있다. 저는 20,000개의 샘플만 가지고 학습해보겠다. tf-idf를 할 때 데이터에 Null 값이 들어있으면 에러가 발생한다. 따라서 tf-idf의 대상이 되는 data의 overview 열에 Null 값이 있는지 확인해야 한다.
data['overview'].isnull().sum()135
135개의 샘플에서 Null 값이 있다고 한다. pandas를 이용하면 Null 값을 처리하는 도구인 fillna()를 사용할 수 있다. 괄호 안에 Null 대신 넣고자하는 값을 넣으면 되는데, 이 경우에는 빈 값(empty value)으로 대체하여 Null 값을 제거한다.
data['overview'] = data['overview'].fillna('')
Null 값을 제거하였다. 이제 .isnull().sum()를 수행하면 0의 값이 나온다. 이제 tf-idf를 수행해보자.
# overview에 대해서 tf-idf 수행
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(data['overview'])
print(tfidf_matrix.shape)(20000, 47487)
overview 열에 대해서 tf-idf를 수행했다. 20,000개의 영화를 표현하기위해 총 47,487개의 단어가 사용되었음을 보여주고 있다. 이제 코사인 유사도를 사용하면 바로 문서의 유사도를 구할 수 있다.
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
코사인 유사도를 구한다.
indices = pd.Series(data.index, index=data['title']).drop_duplicates()
print(indices.head())
영화의 타이틀과 인덱스를 가진 테이블을 만든다. 이 중 5개만 출력해보도록 하겠다.
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
dtype: int64
이 테이블의 용도는 영화의 타이틀을 입력하면 인덱스를 리턴하기 위함이다.
idx = indices['Father of the Bride Part II']
print(idx)4
이제 선택한 영화에 대해서 코사인 유사도를 이용하여 가장 overview가 유사한 10개의 영화를 찾아내는 함수를 만든다.
def get_recommendations(title, cosine_sim=cosine_sim):
# 선택한 영화의 타이틀로부터 해당되는 인덱스를 받아옵니다. 이제 선택한 영화를 가지고 연산할 수 있습니다.
idx = indices[title]
# 모든 영화에 대해서 해당 영화와의 유사도를 구합니다.
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 영화들을 정렬합니다.
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 가장 유사한 10개의 영화를 받아옵니다.
sim_scores = sim_scores[1:11]
# 가장 유사한 10개의 영화의 인덱스를 받아옵니다.
movie_indices = [i[0] for i in sim_scores]
# 가장 유사한 10개의 영화의 제목을 리턴합니다.
return data['title'].iloc[movie_indices]
영화 다크 나이트 라이즈와 overview가 유사한 영화들을 찾아보겠다.
get_recommendations('The Dark Knight Rises')12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
10122 Batman Begins
Name: title, dtype: object
가장 유사한 영화가 출력되는데, 영화 다크 나이트가 첫번째고, 그 외에도 전부 배트맨 영화를 찾아낸 것을 확인할 수 있다.
'IT > Data Science' 카테고리의 다른 글
| .iteritems() 함수 (0) | 2021.10.29 |
|---|---|
| [딥러닝을 이용한 자연어 처리 입문] 5. 벡터의 유사도(Vector Similarity) - 2. 여러가지 유사도 기법 (0) | 2021.10.20 |
| [Elasticsearch] Elastic Cloud에서 Nori Tokenizer 설치하기 (Extensions 활용) (0) | 2021.10.19 |
| [딥러닝을 이용한 자연어 처리 입문] 6. 토픽 모델링(Topic Modeling)- 3) 잠재 디리클레 할당(LDA) 실습2 (2) | 2021.10.14 |
| [딥러닝을 이용한 자연어 처리 입문] 6. 토픽 모델링(Topic Modeling)- 2) 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA) (0) | 2021.10.14 |

