

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 파이썬알고리즘
- heap
- GenerativeAI
- LeetCode
- codeup
- Greedy
- dfs
- Python3
- Python
- GenAI
- medium
- 투포인터
- sql코테
- nlp
- 릿코드
- Stack
- 슬라이딩윈도우
- stratascratch
- 파이썬
- 자연어처리
- SQL
- 니트코드
- 생성형AI
- slidingwindow
- 알고리즘
- 리트코드
- gcp
- 코드업
- 파이썬기초100제
- two-pointer
Archives
- Today
- Total
Tech for good
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 8. Transformer Models and BERT Model 본문
IT/Cloud
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 8. Transformer Models and BERT Model
Diana Kang 2023. 9. 9. 20:32https://www.youtube.com/playlist?list=PLIivdWyY5sqIlLF9JHbyiqzZbib9pFt4x
Generative AI Learning Path
https://goo.gle/LearnGenAI
www.youtube.com


- RNN/LSTM -> Sequence-to-sequence model
- i.e. Translation, Text classification
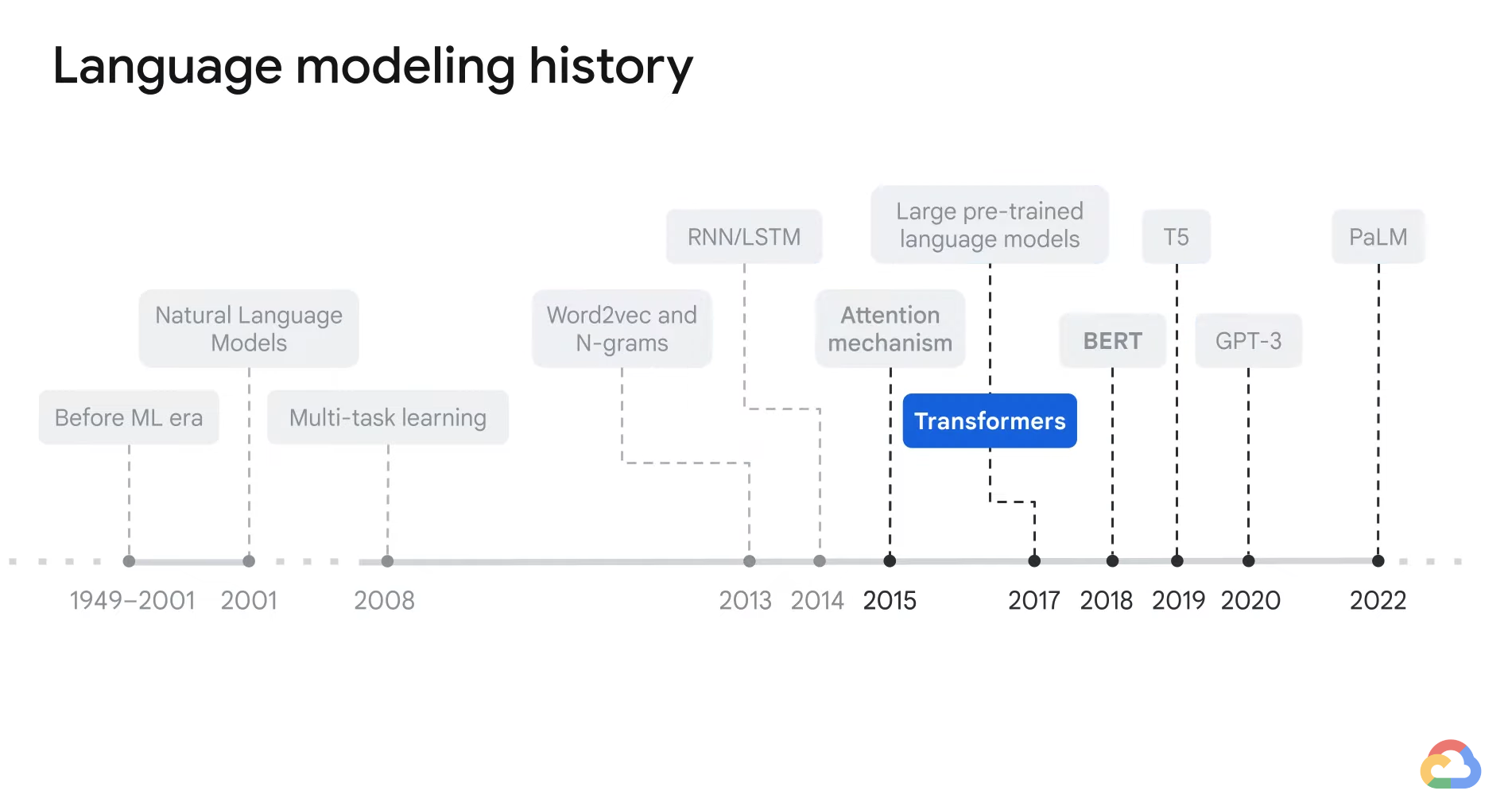

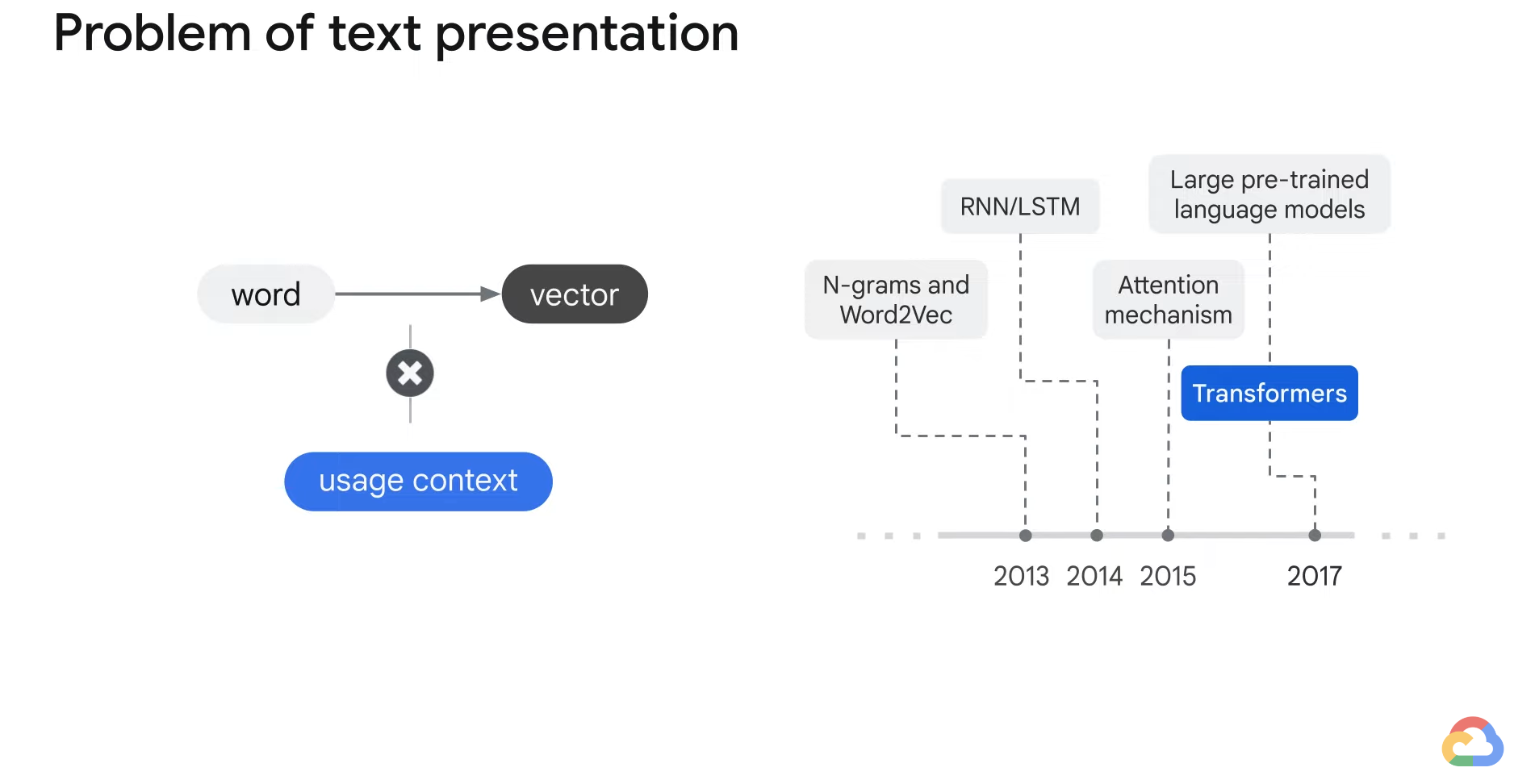
- Although all the models before Transformers were able to represent words as vectors, these vectors did not contain the context.
- And the usage of words changes based on the context before attention mechanisms came about.
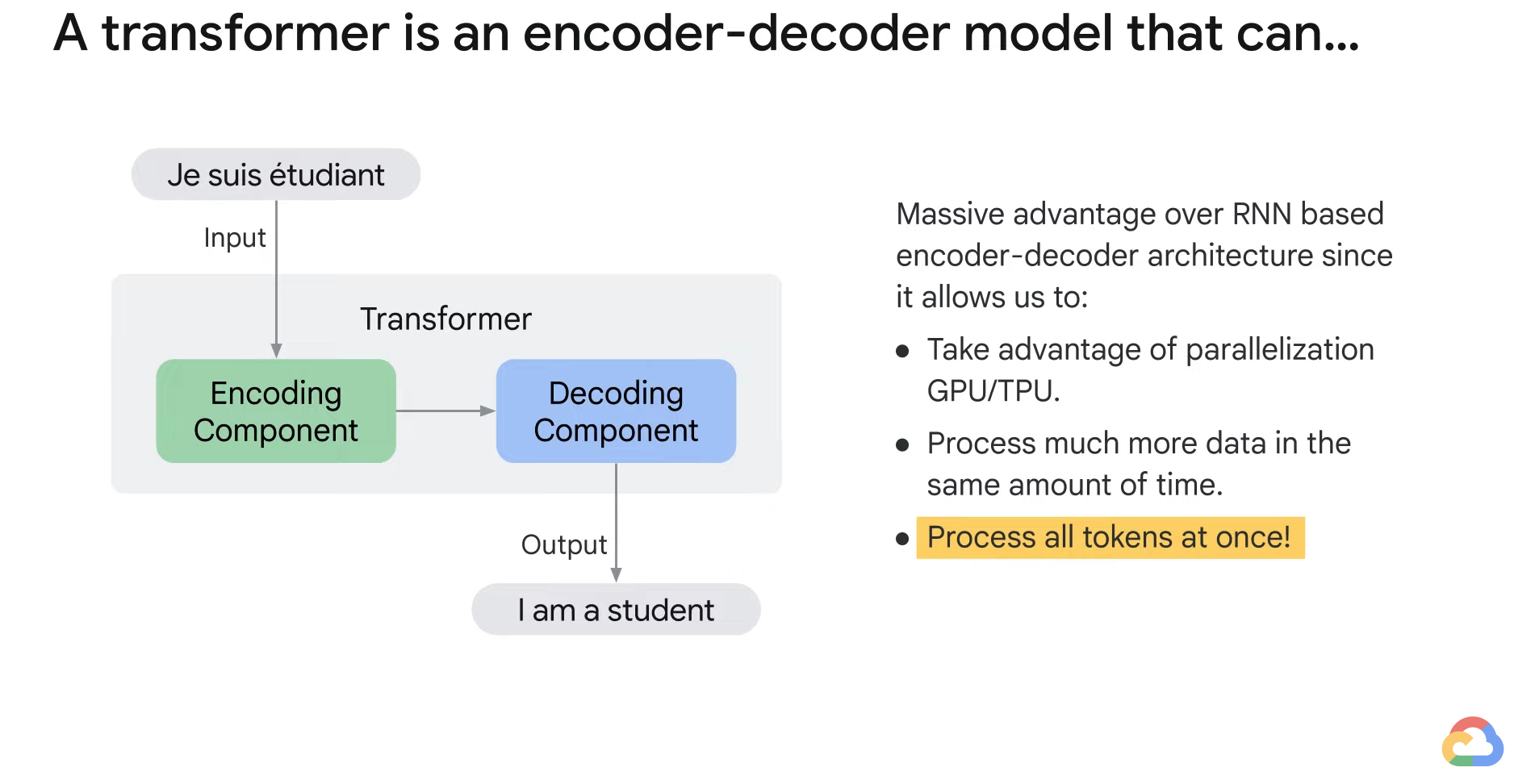
- A transformer is an encoder-decoder model that uses the attention mechanism.
- It can take advantages of pluralization and also process a large amount of data at the same time because of its model architecture.
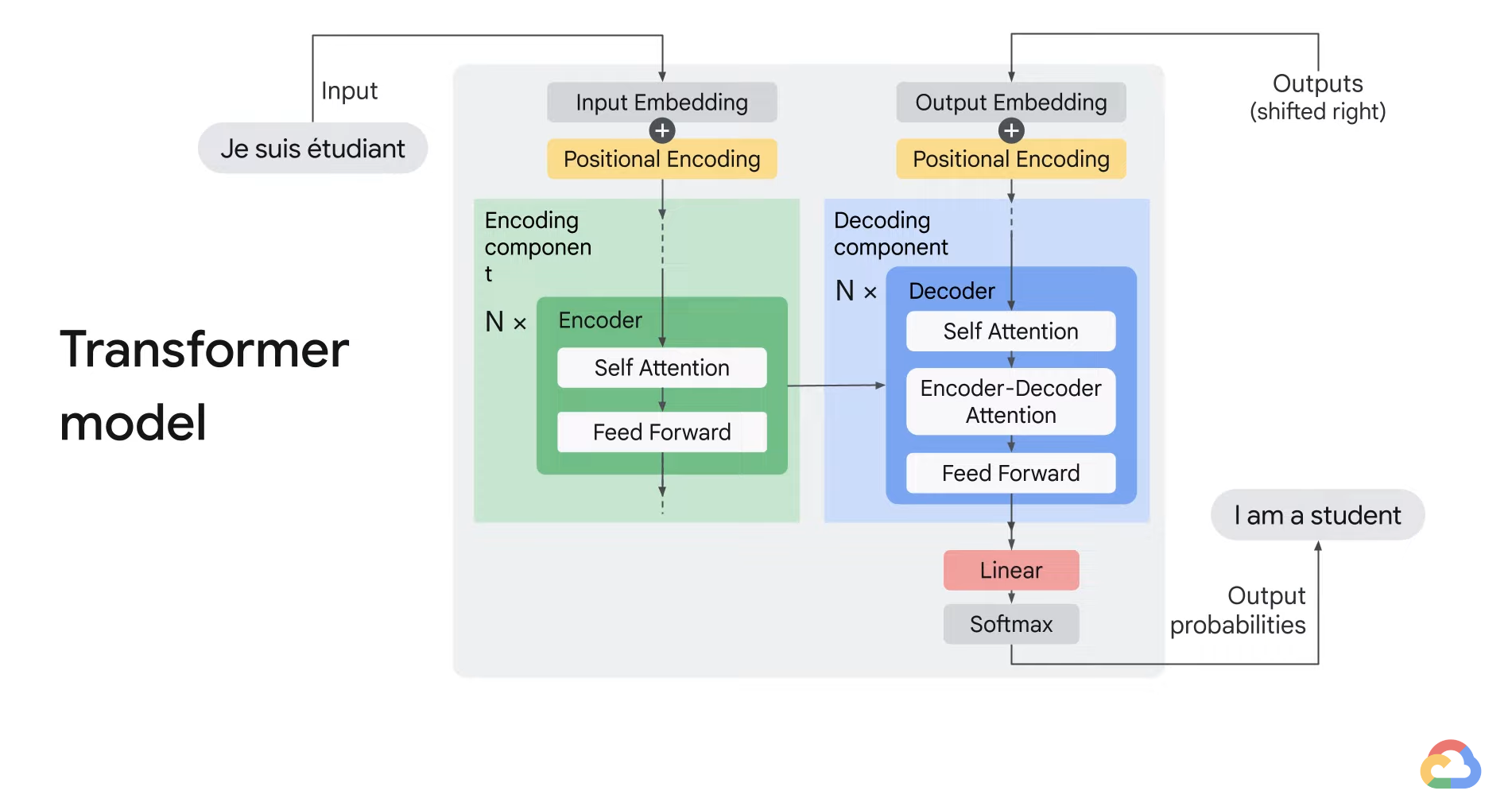
- Attention mechanism helps improve the performance of machine translation applications.
- Transformer models were built using attention mechanisms at the core.
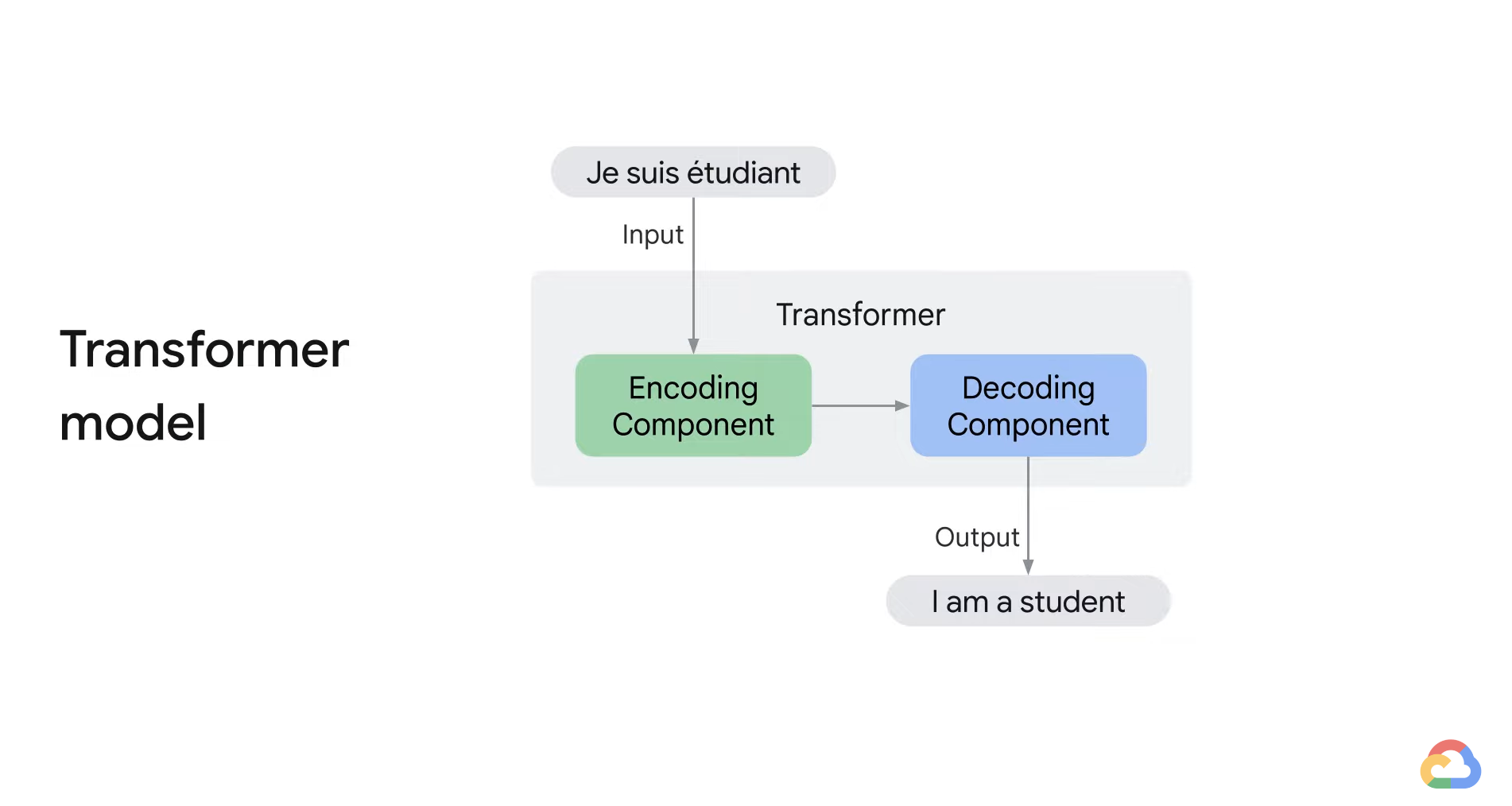
- A transformer model consists of encoder and decoder.
- The encoder encodes the input sequence and passes it to the decoder.
- The decoder decodes the representation for a relevant task.
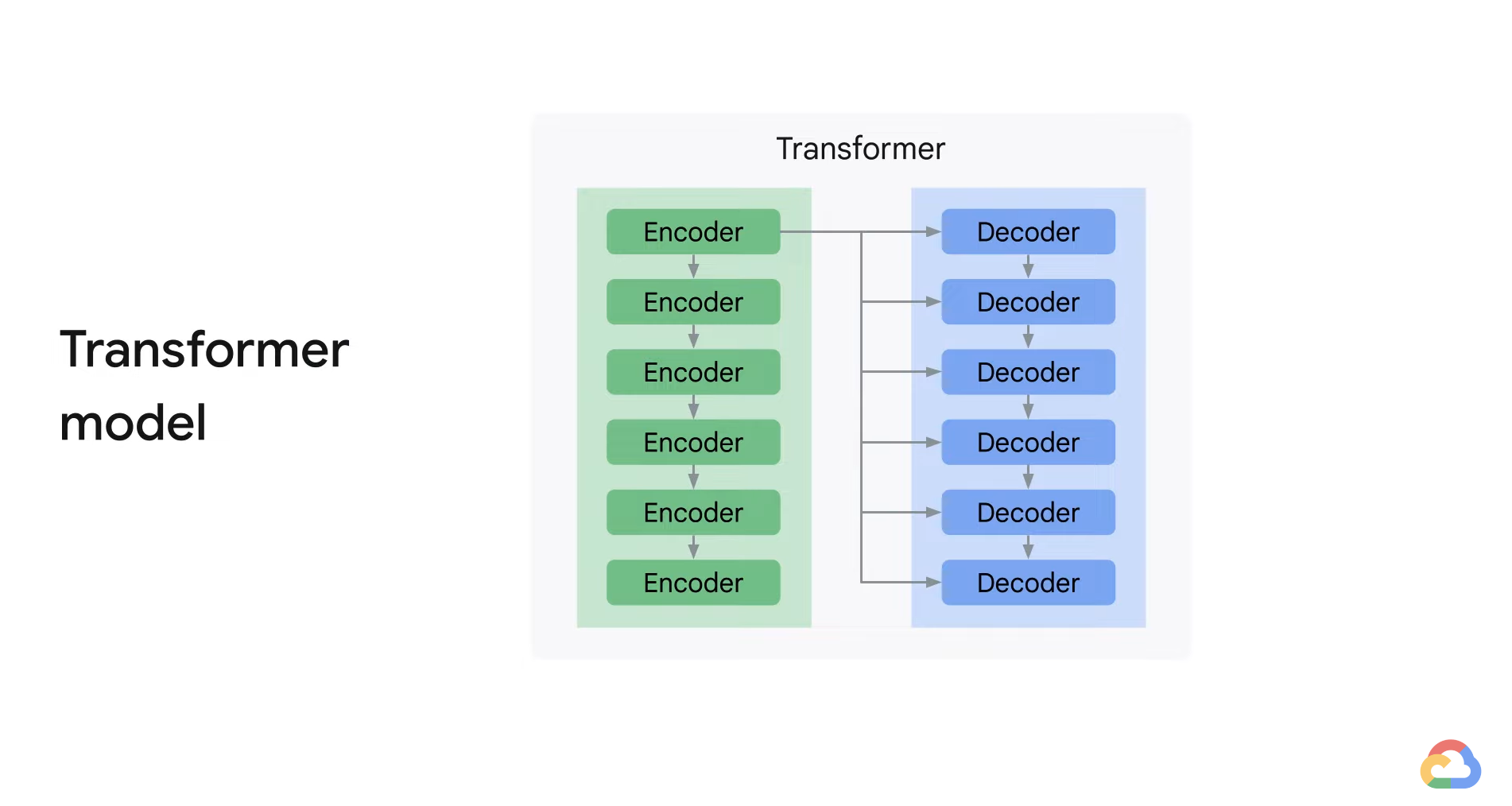
- The encoding component is a stack of encoders of the same number.
- Transformers stack six encodes on top of each other.
- Six is a hyperparameter.
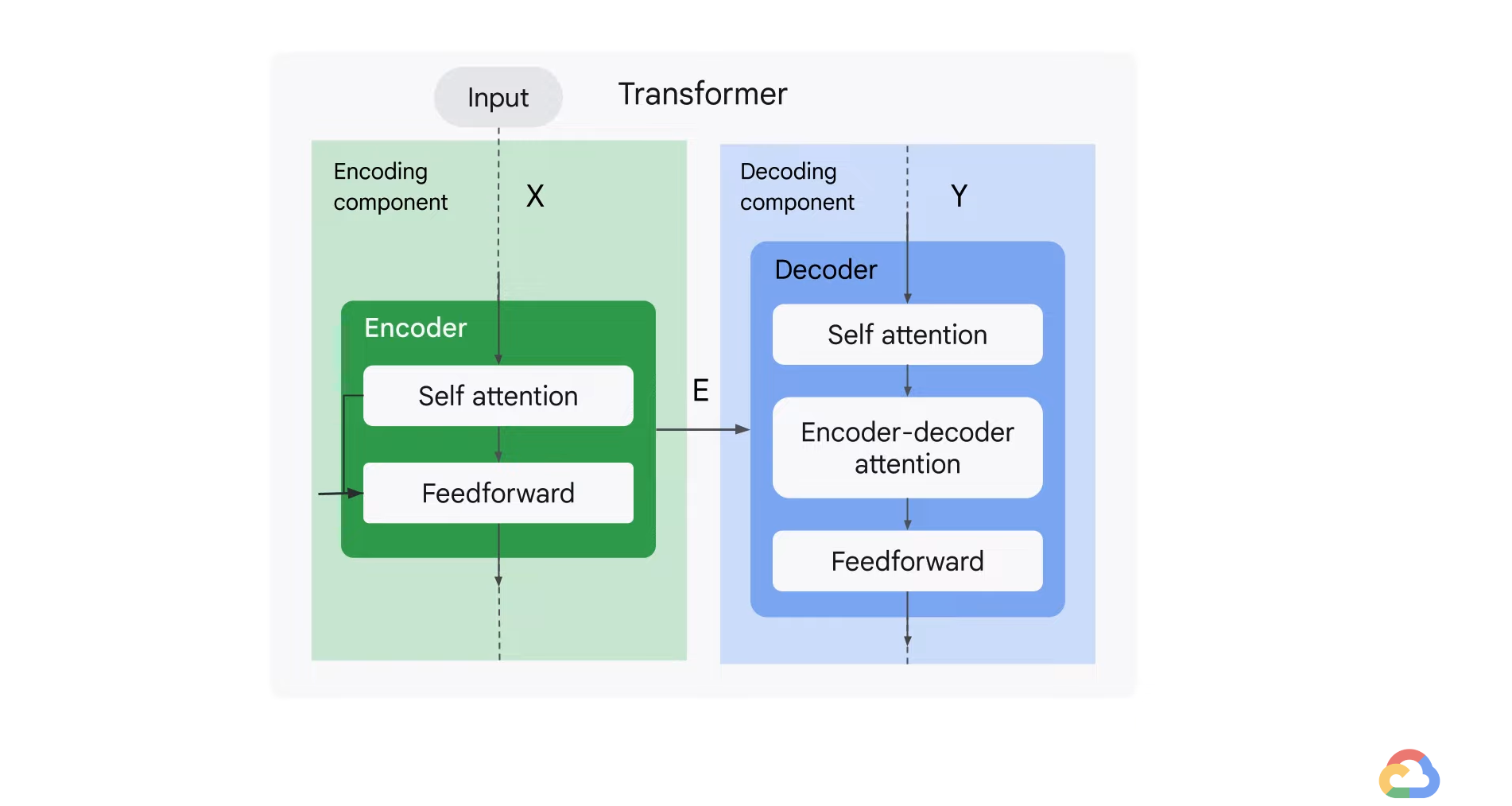
- The encoders are all identical in structure but with different weights.
- Each encoder can be broken down into two sub-layers.
- The first layer - Self attention
- It helps to encode or look at relevant part of the words as it encodes a central word in the input sentence.
- The second layer - Feedforward
- The output of the self-attention layer is fed to the feedforward neural network.
- It is independently applied to each position.
- The first layer - Self attention
- The decoder has both the self attention and the feedforward layer, but between them is the encoder-decoder, attention layer that helps a decoder focus on relevant parts of the input sentence.
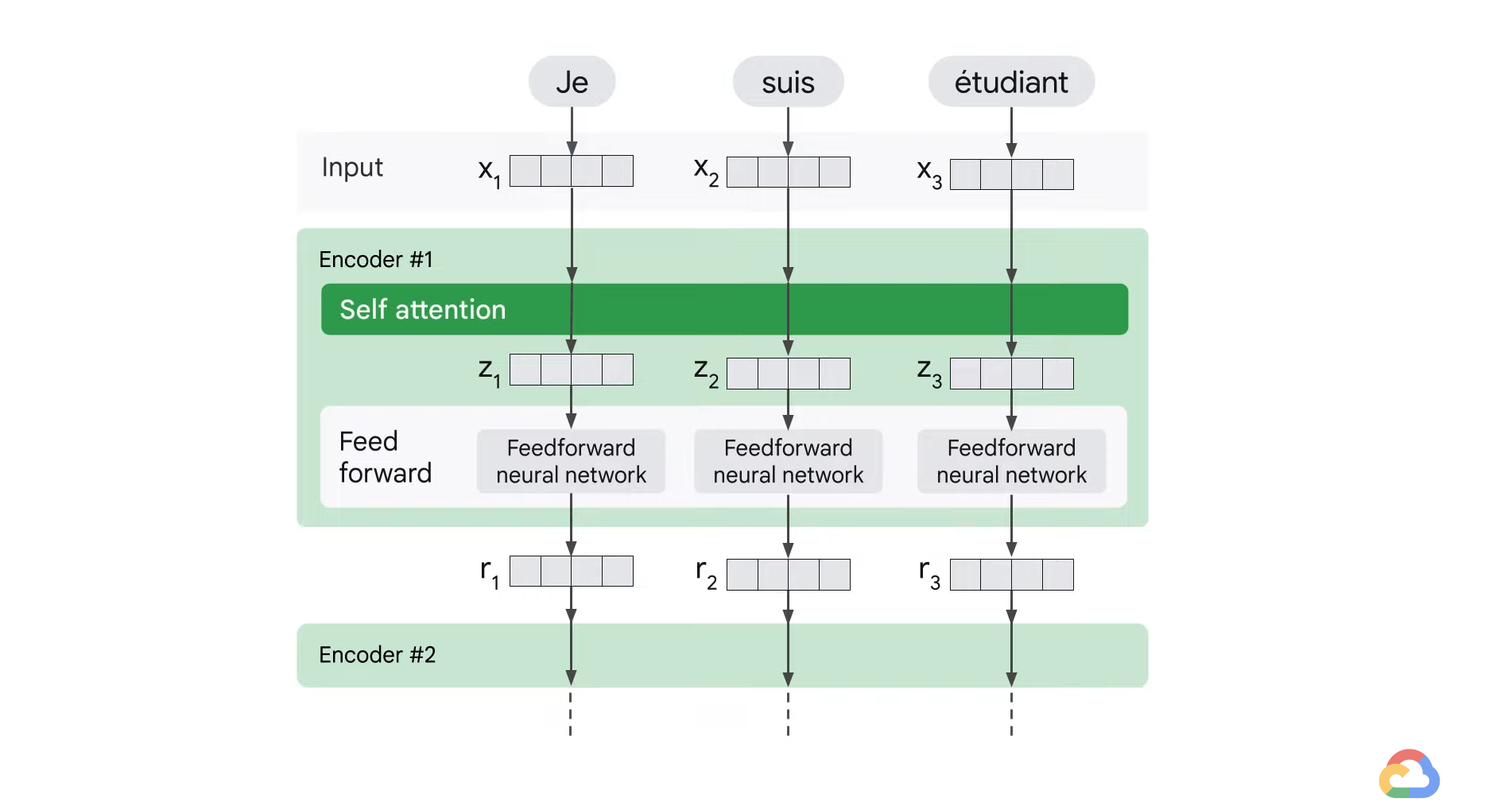
- After embedding the words in the input sequence, each of the embedding vector flows through the two layers of the encoder.
- The word at each position passes through a self attention process then it passes through a feedforward neural network.
- The exact same network with each vector flowing through it separately.
- Dependencies exist between these paths in the self attention layer.
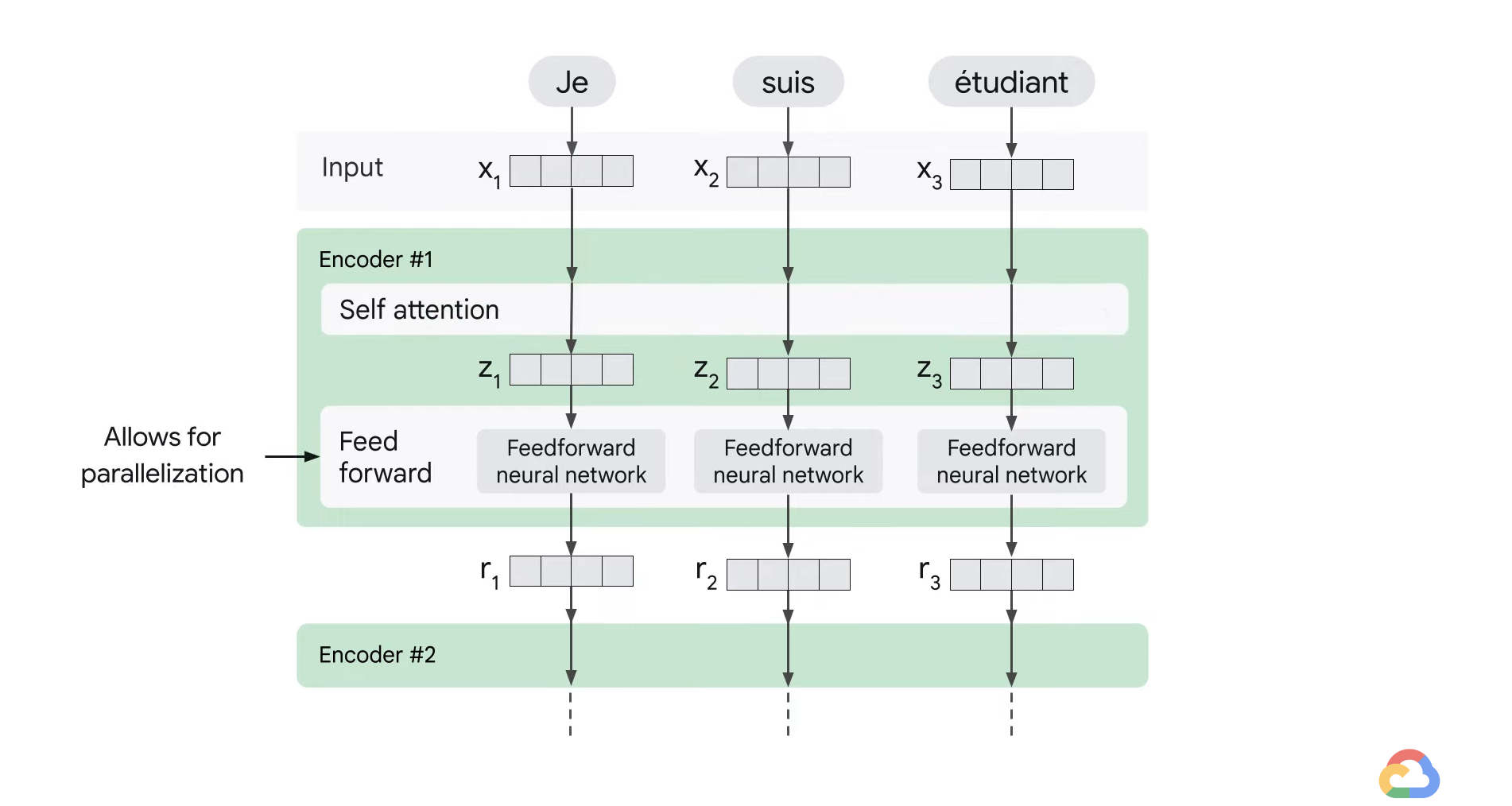
- However, the feedforward layer does not have these dependencies and therefore various paths can be executed in parallel while they flow through the feedforward layer.
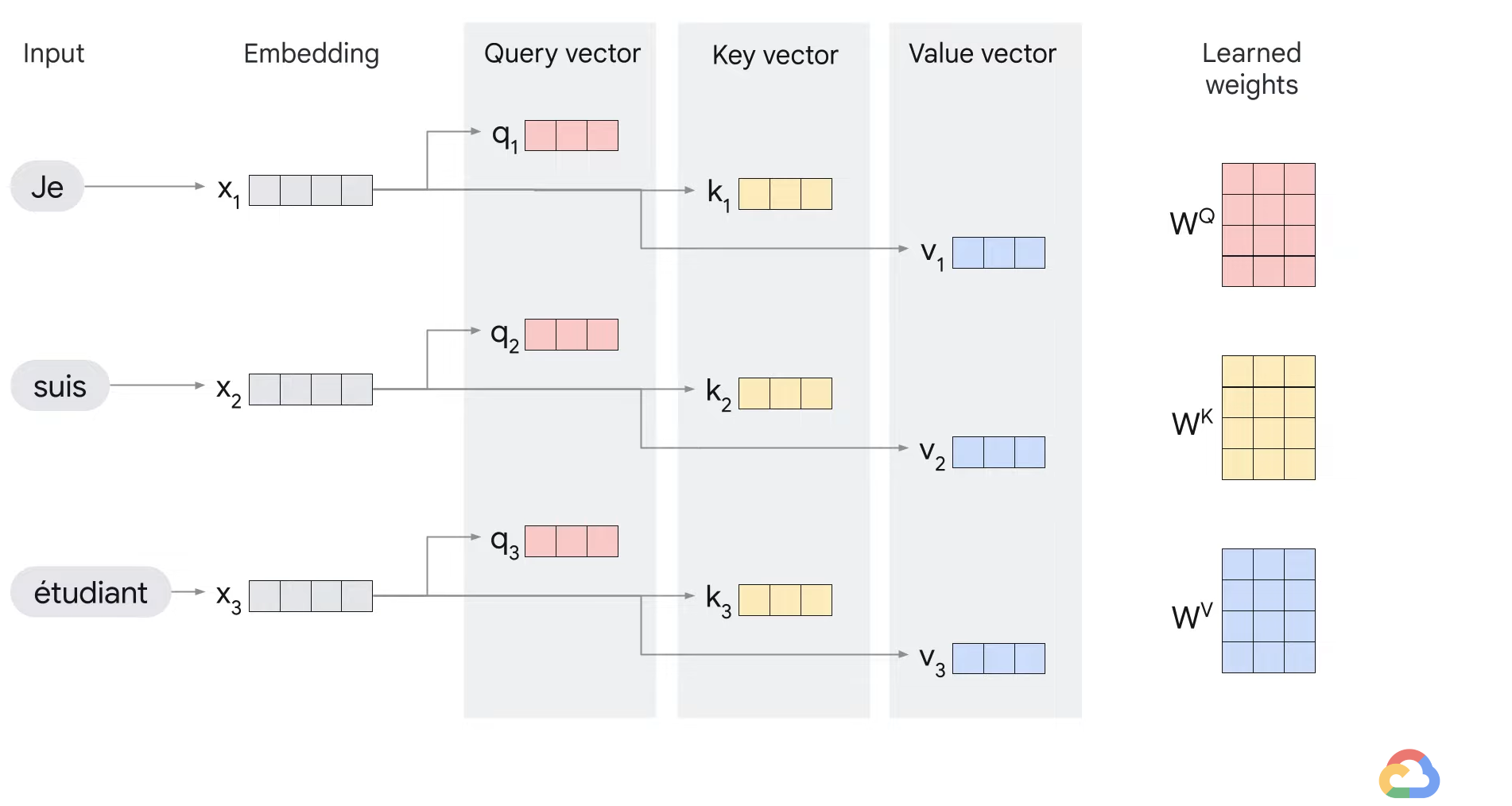
- In the self attention layer, the input embedding is broken up into query, key, and value vectors.
- These vectors are computed using weights that the transformer learns during the training process.
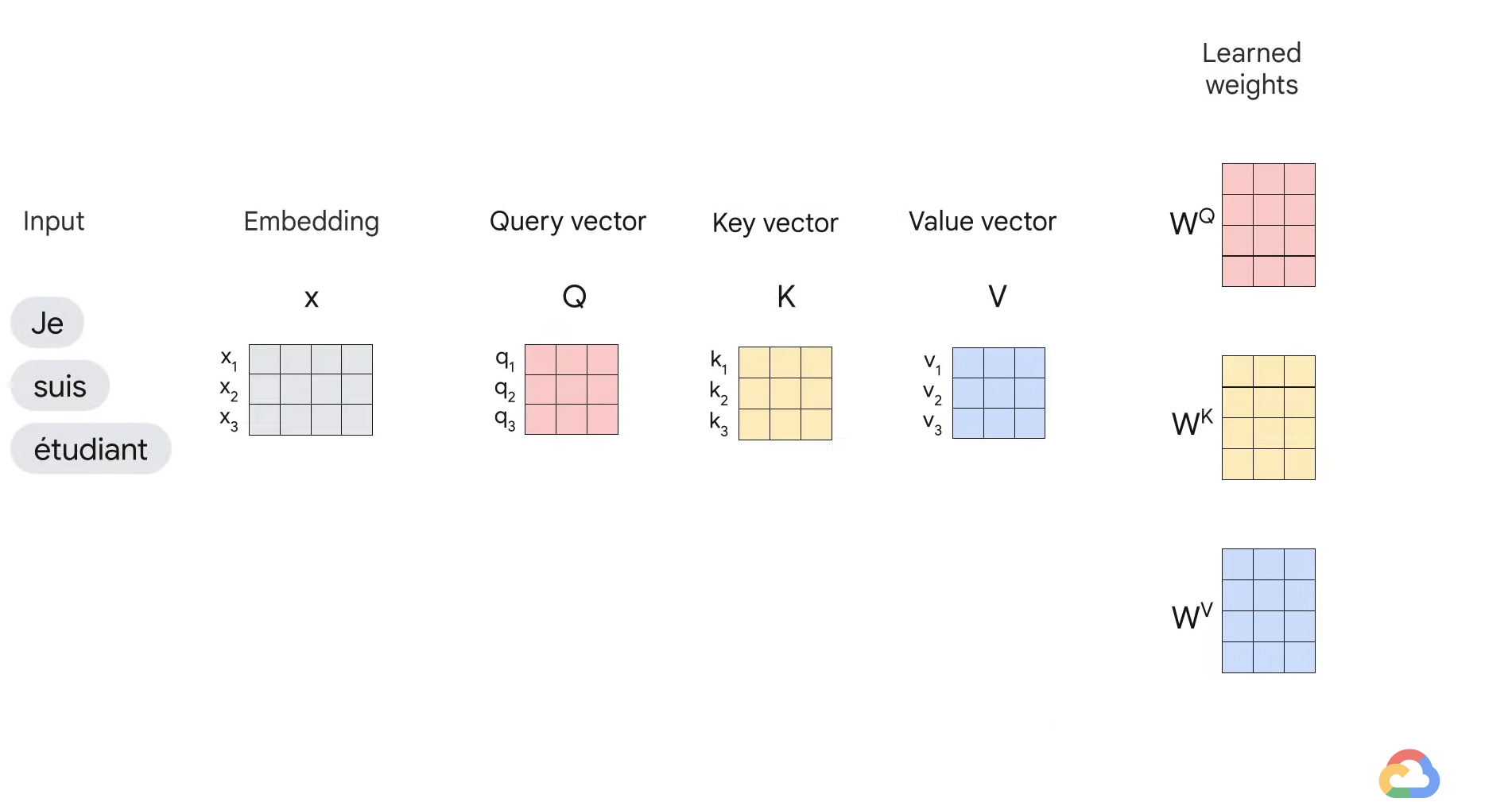
- All of these computations happen in parallel in the model, in the form of matrix computation.
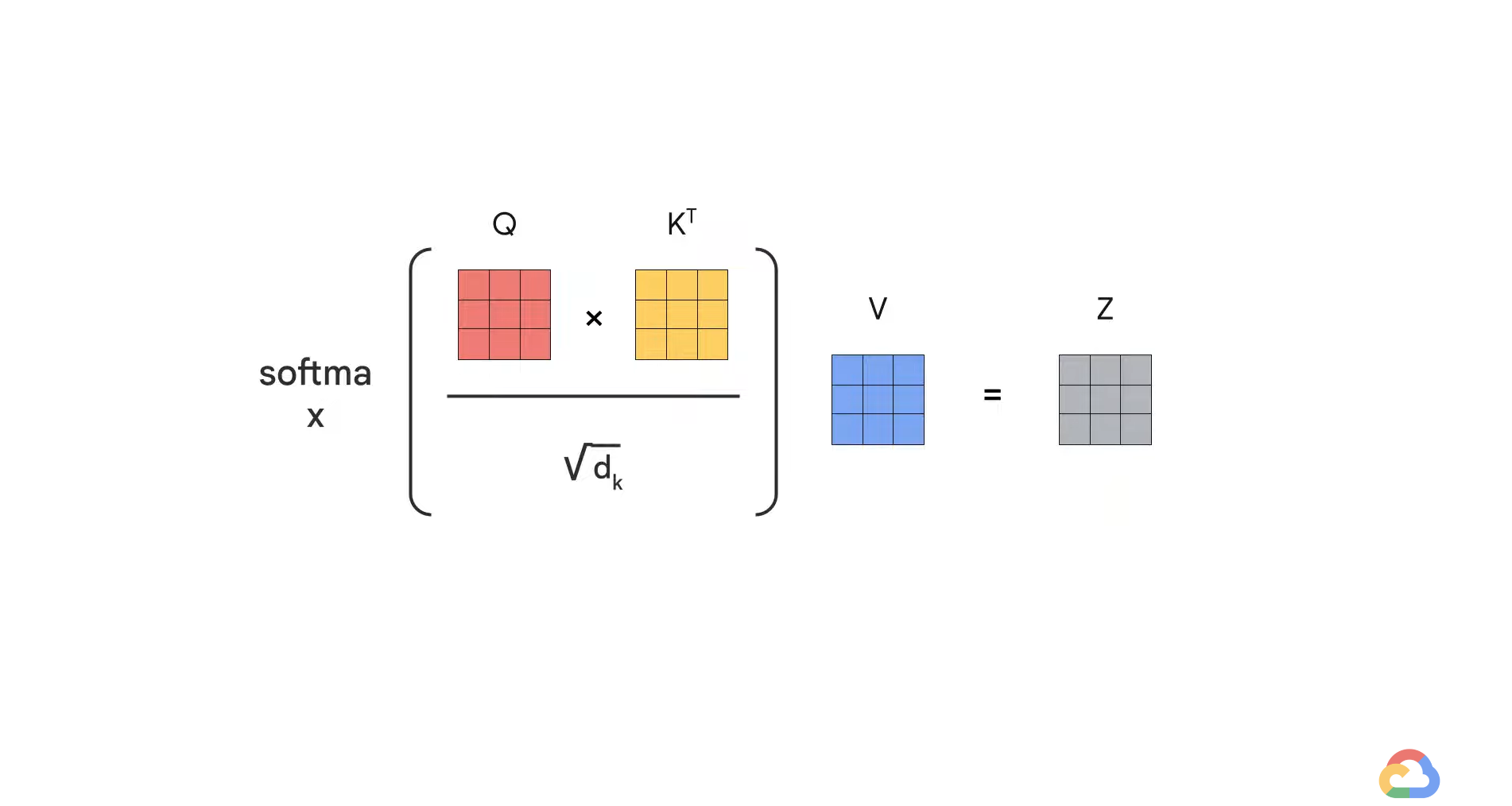
- Once we have the query, key, and value vectors, the next step is to multiply each value vector by the soft max score to sum them up.
- The intention is to keep intact the values of the words you want to focus on and leave out irrelevant words by multiplying them by tiny numbers (i.e. 0.001).
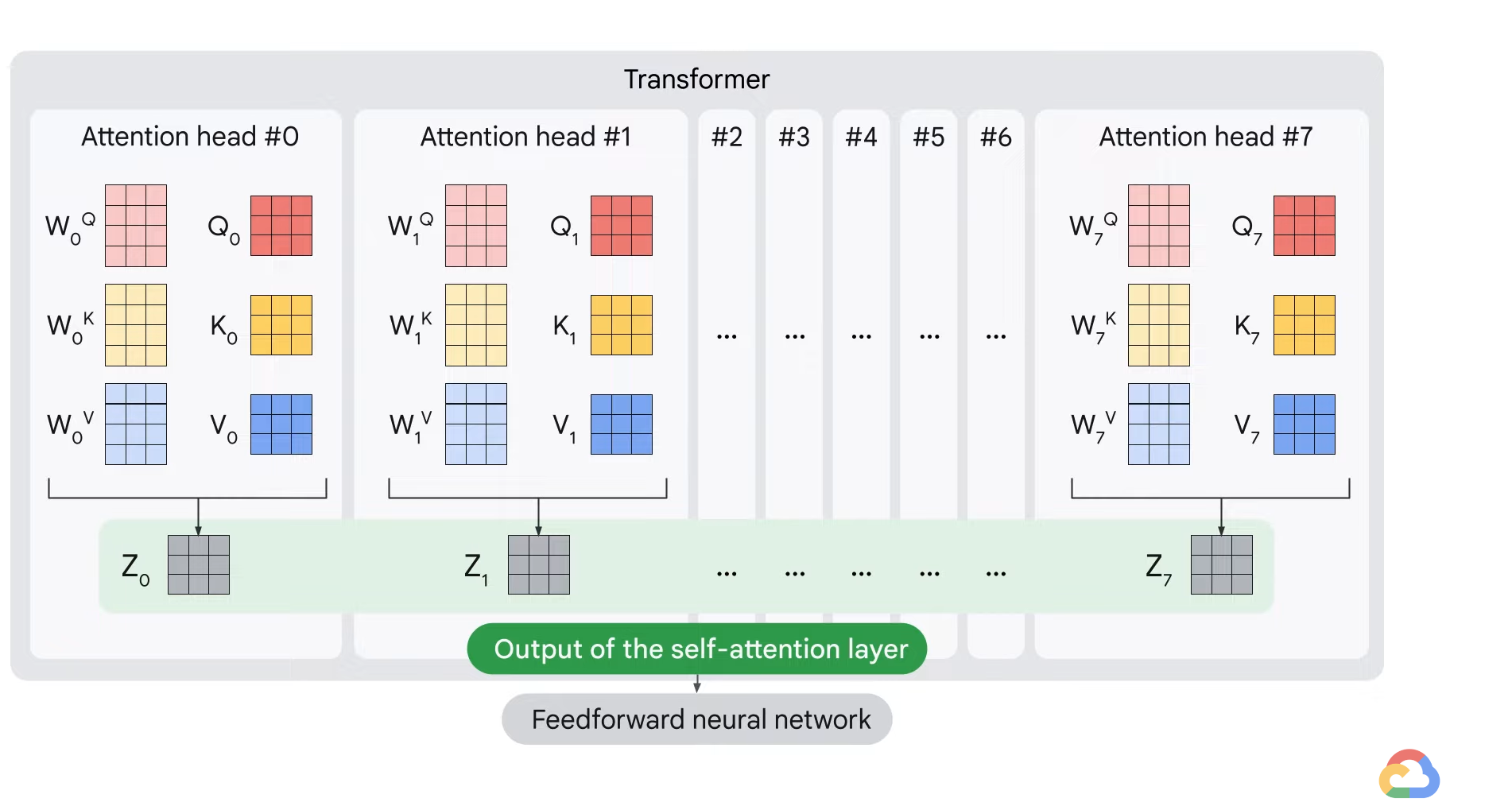
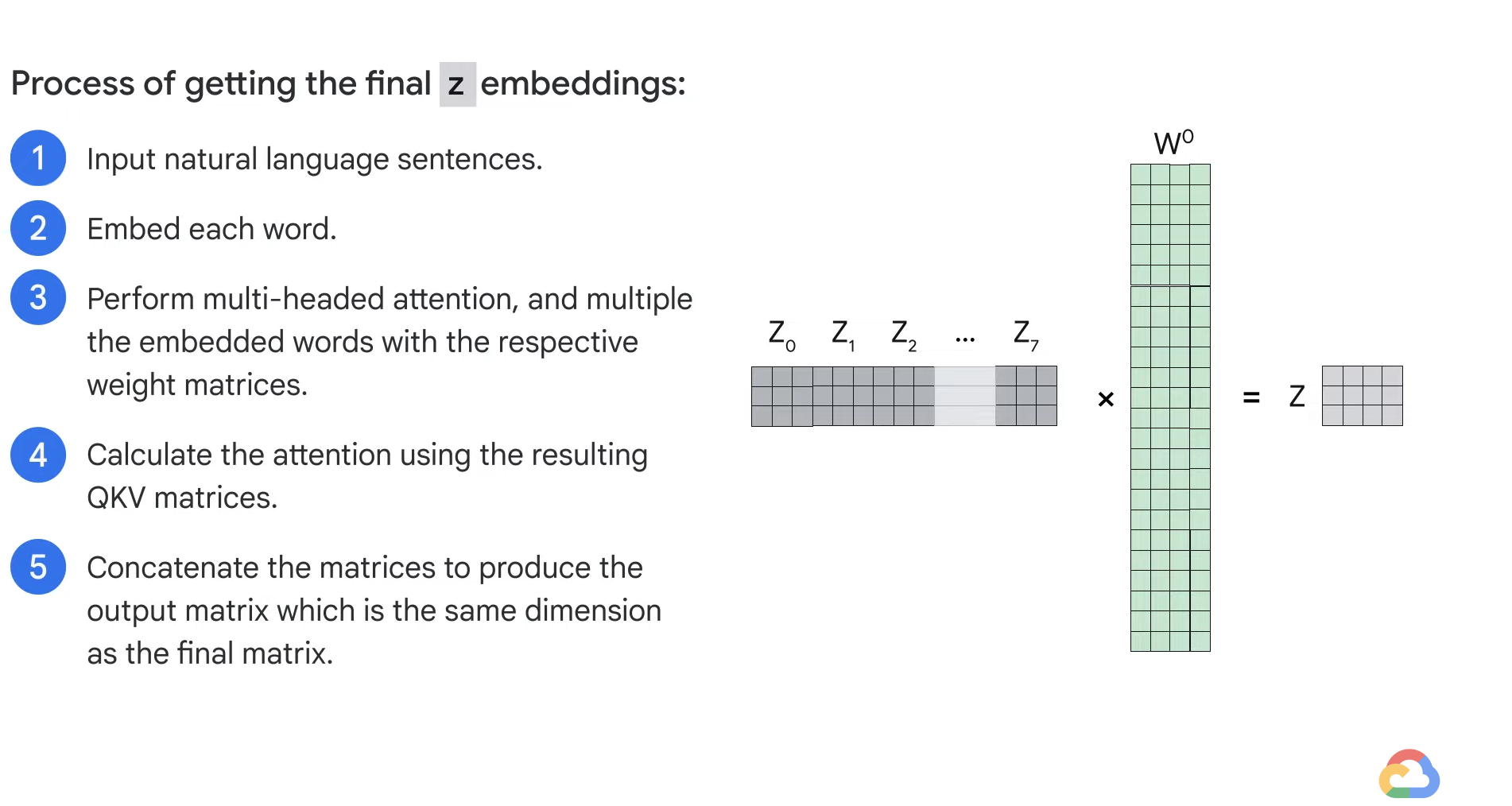
- Next, we have to sum up the weighted value vectors which produce the output of the self attention layer at this position.
- For the first word, you can send along the resulting vector to the feedforward neural network.
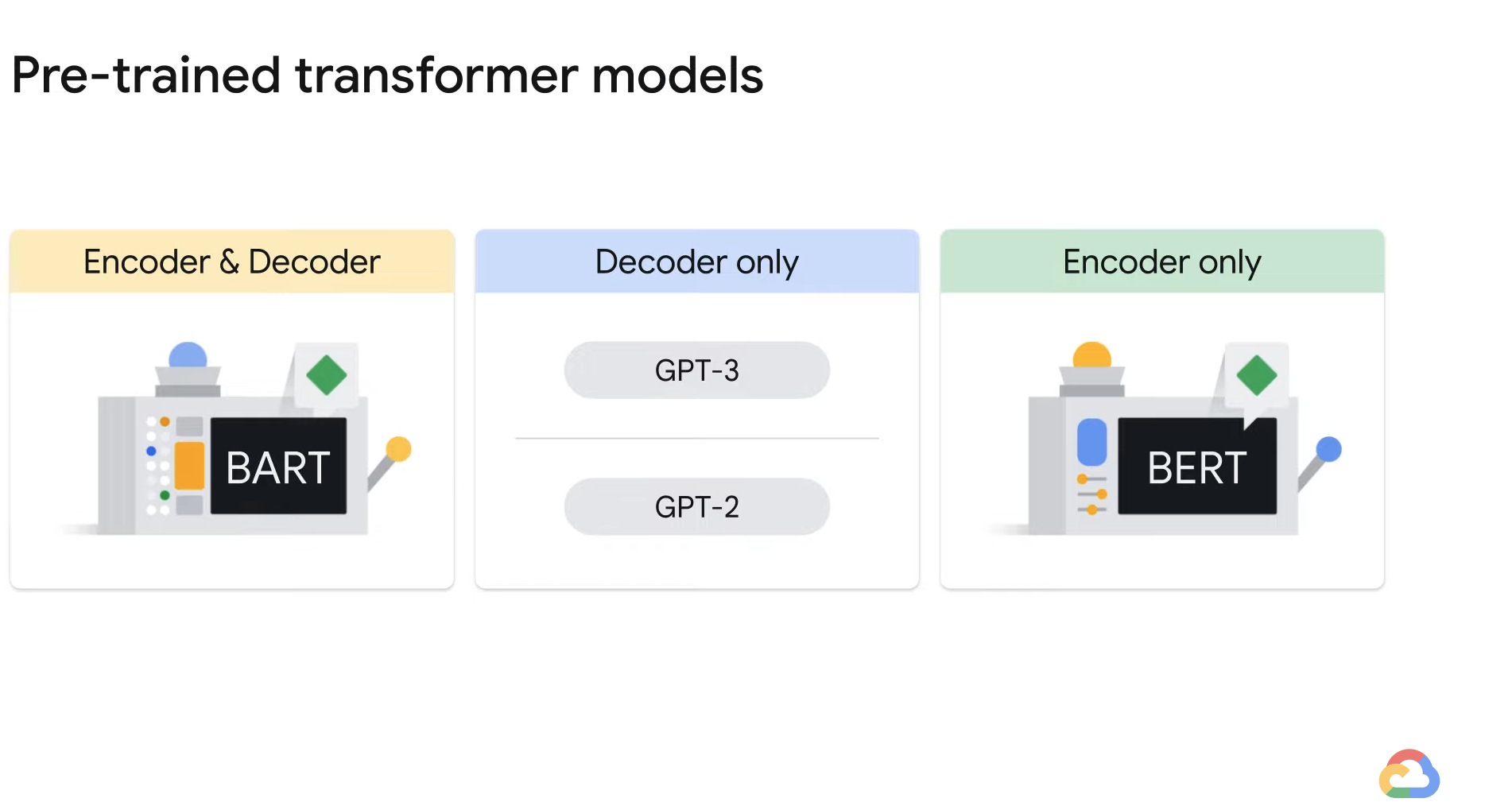
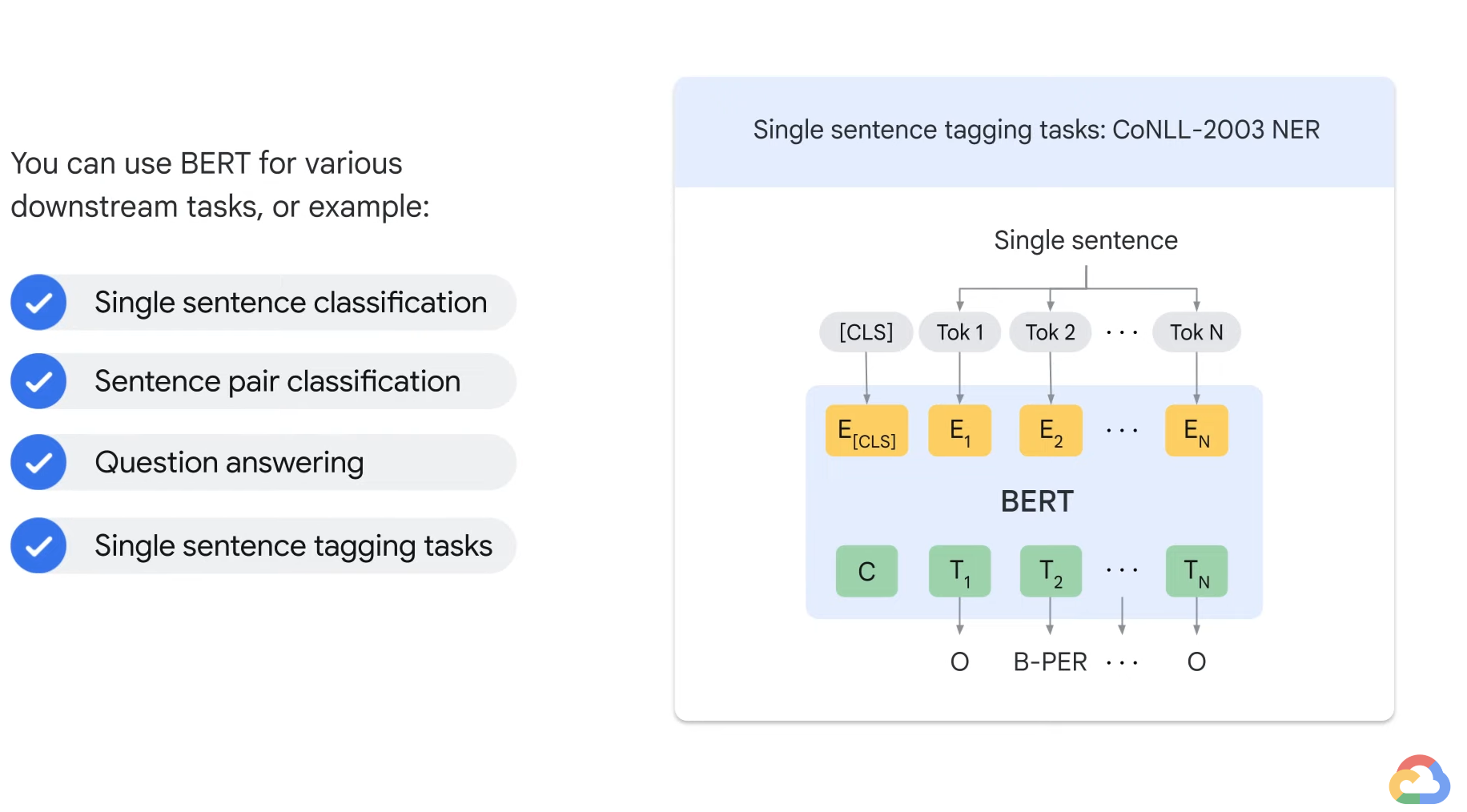
- A popular encoder-only architecture is BERT.
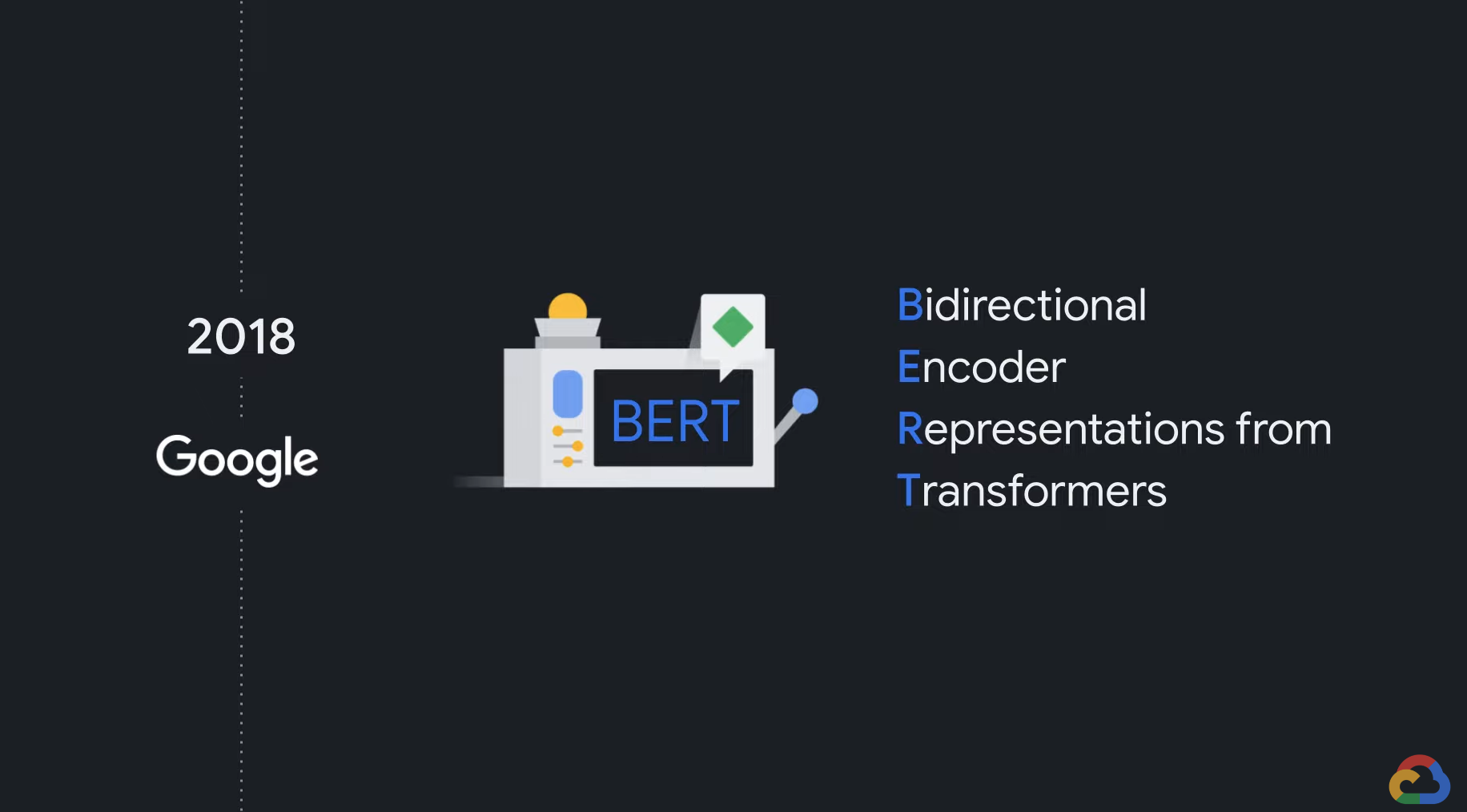
- BERT is one of the trained transformer models.
- BERT stands for Bidirectional Encoder Representations from Transformers, and was developed by Google in 2018.

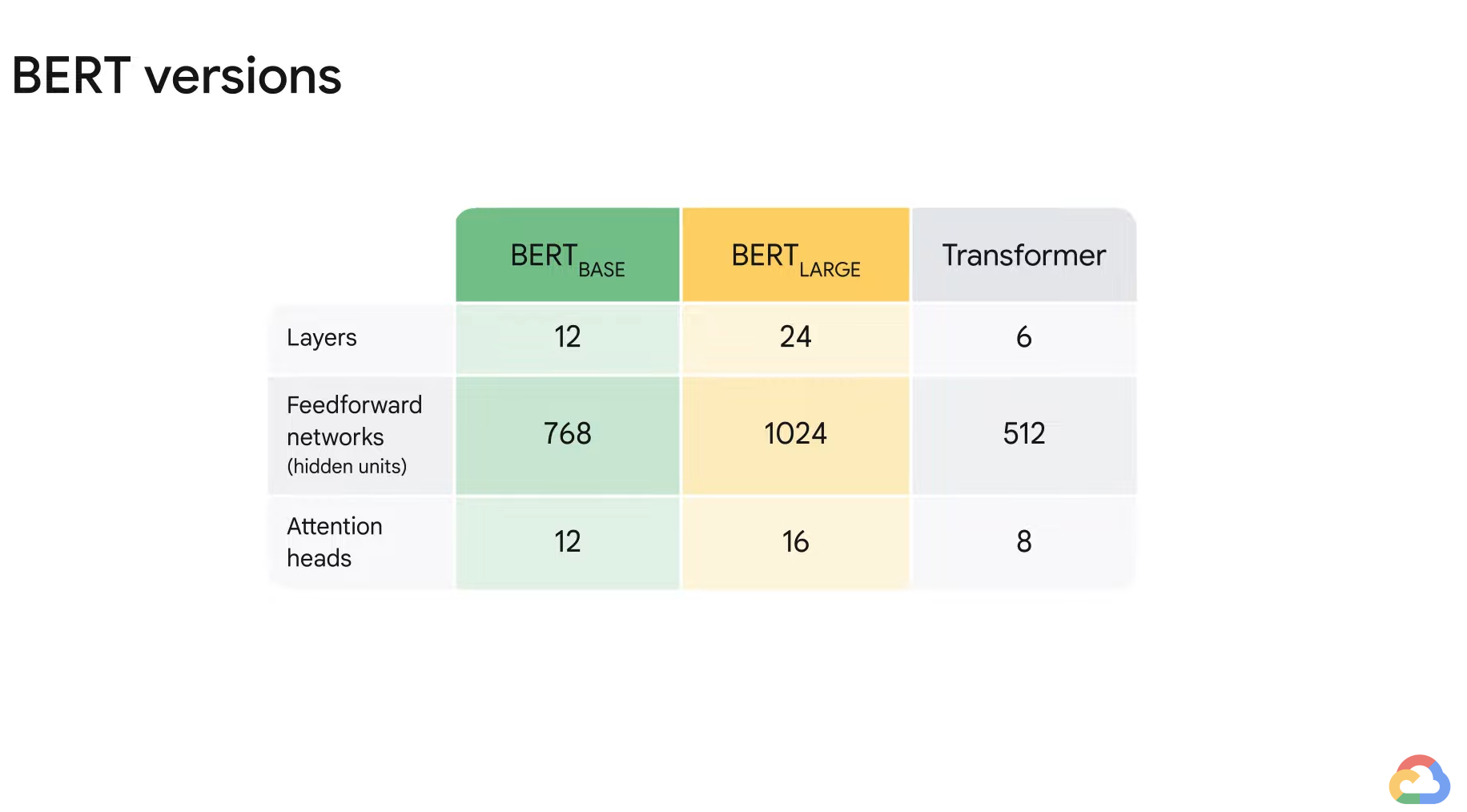
- BERT was trained in two variations.
- 1) BERT Base
- It has 12 layers of Transformer with about 110 million parameters.
- 2) BERT Large
- It has 24 layers of Transformer with about 340 million parameters.
- 1) BERT Base
- The tasks work at both a sentence level and a token level.
- The way that BERT works is was trained on two different tasks.
Task 1) Masked language modeling (MLM)
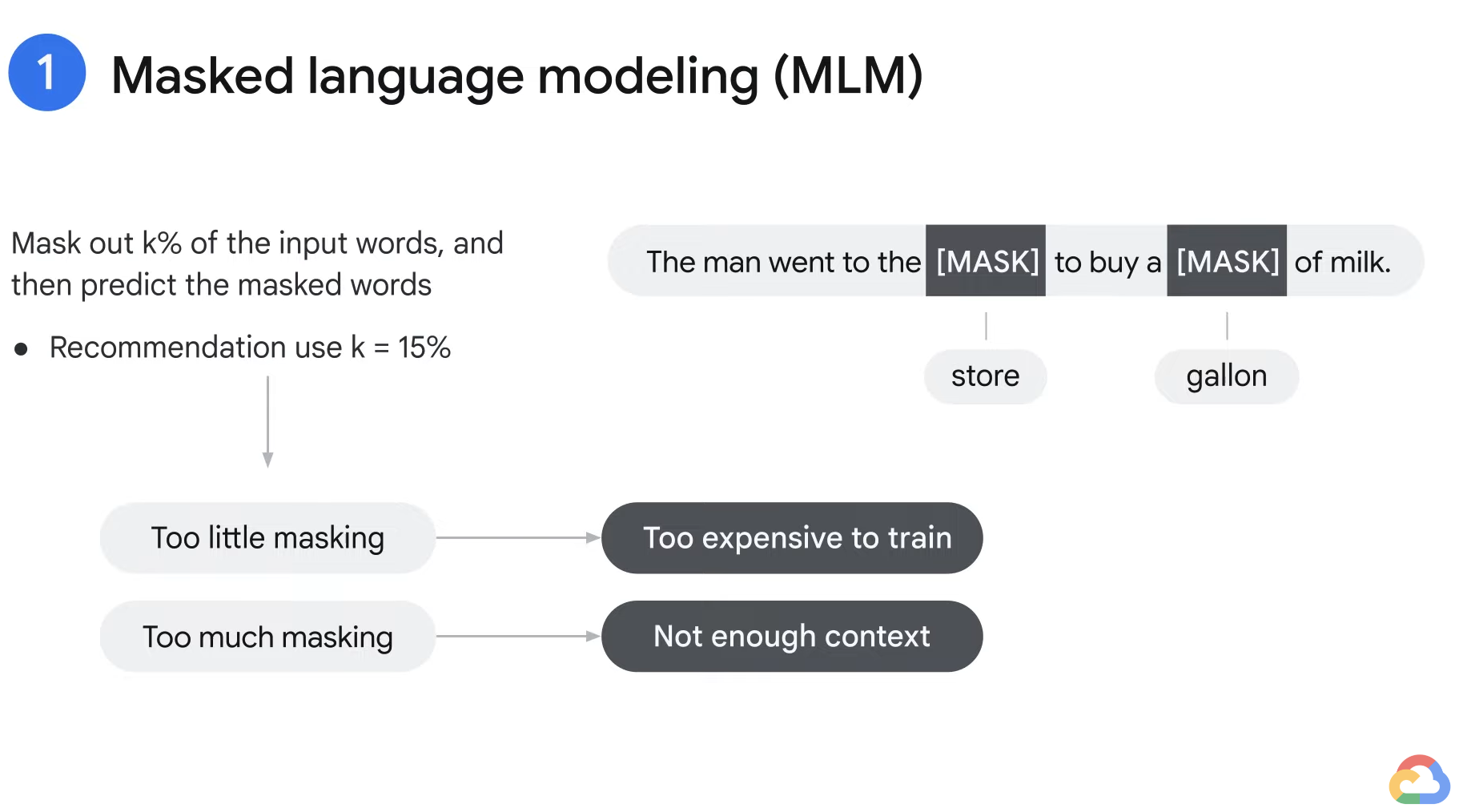
- The sentences are masked and the model is trained to predict the masked words.
- If you were to train BERT from scratch, you would have to mask a certain percentage of the words in your corpus. (The recommended percentage for masking is 15%.)
- The masking percentage achieves a balance between too little and too much masking.
Task 2) Next sentence prediction (NPS)

- BERT aims to learn the relationships between sentences and predict the next sentence given the first one.
- BERT is responsible for classifying if sentence B is in the next sentence after sentence A (Binary Classification task).

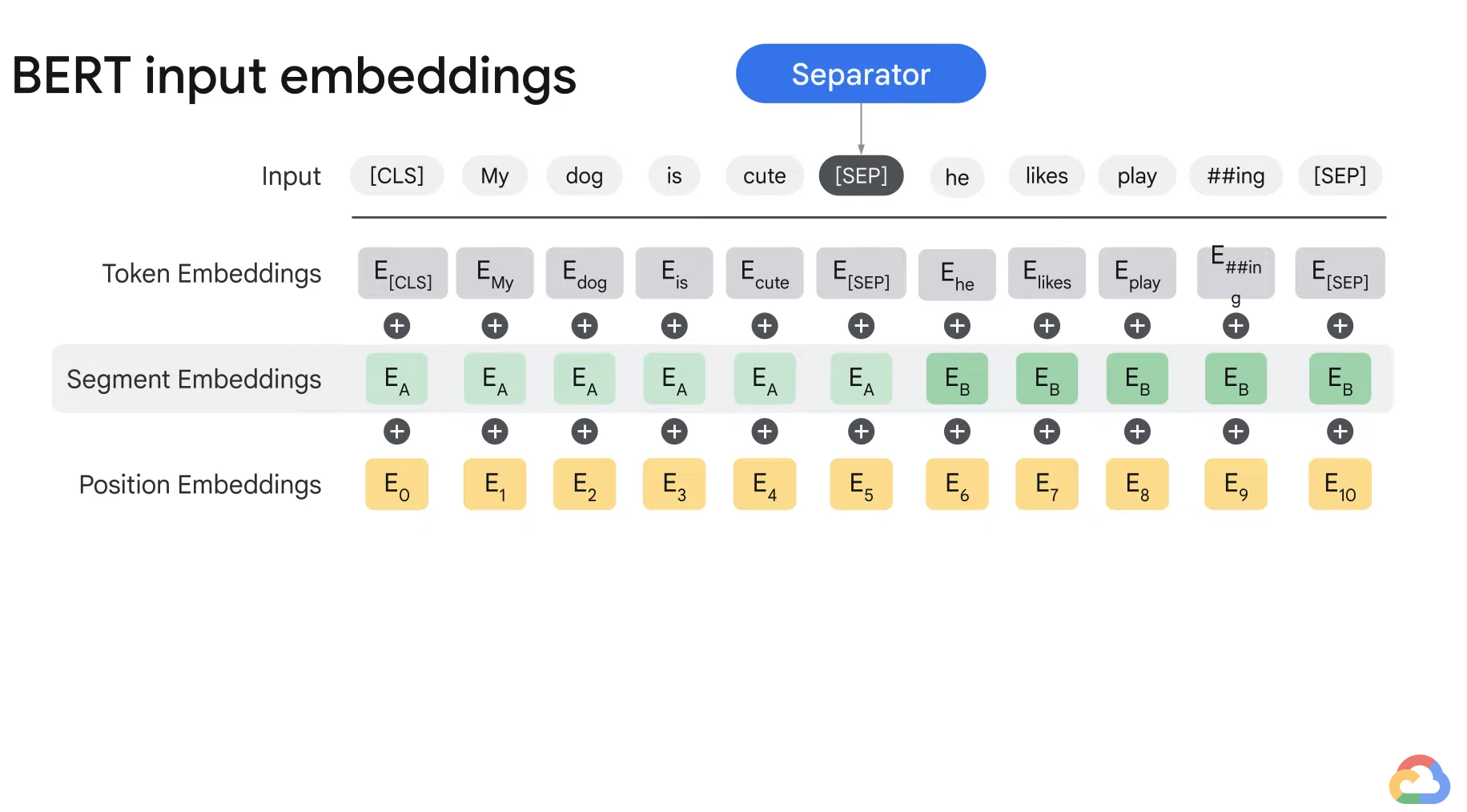

- In order to train BERT, you need to feed three different kinds of embeddings to the model.
- For the input sentence, you get three different embeddings:
- Token, Segment, Position Embeddings
- 1) Token embedding
- It is a representation of each token as an embedding in the input sentence.
- The words are transformed into vector representations of certain dimensions.
- 2) Segment embedding
- There is a special token represented by SEP that separates the two different splits of the sentence.
- 3) Position embedding
- There is a special token represented by SEP that separates the two different splits of the sentence.
- 1) Token embedding
- Token, Segment, Position Embeddings









'IT > Cloud' 카테고리의 다른 글
'IT/Cloud' Related Articles
more



