| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 자연어처리
- 투포인터
- gcp
- nlp
- Microsoft
- 생성형AI
- GenerativeAI
- dfs
- medium
- two-pointer
- 슬라이딩윈도우
- 파이썬알고리즘
- 알고리즘
- 파이썬기초100제
- 구글퀵랩
- Python3
- Blazor
- 니트코드
- slidingwindow
- 리트코드
- sql코테
- 파이썬
- Python
- 코드업
- GenAI
- 릿코드
- SQL
- LeetCode
- codeup
- stratascratch
- Today
- Total
Tech for good
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 9. Create Image Captioning Models 본문
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 9. Create Image Captioning Models
Diana Kang 2023. 9. 30. 15:31https://www.youtube.com/playlist?list=PLIivdWyY5sqIlLF9JHbyiqzZbib9pFt4x
Generative AI Learning Path
https://goo.gle/LearnGenAI
www.youtube.com

Introduction


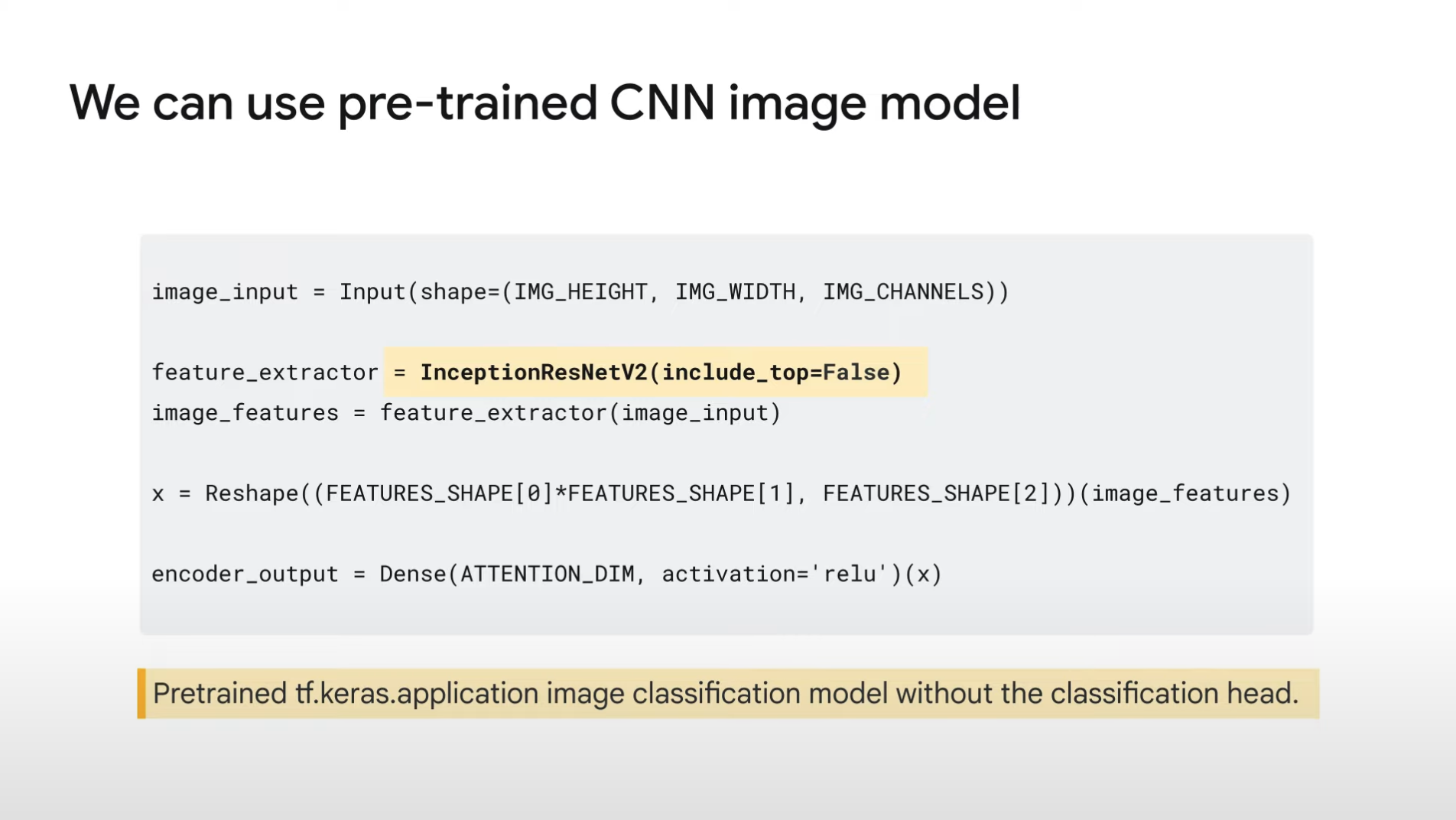
1. Pass images to encoder
2. Extract information from the images
3. Create some feature vectors
4. Vectors are passed to the decoder
5. Build captions by generating words, one by one.

Decoder


- It gets words one by one and makes the information of words and images, which is coming from the encoder output.
- And tries to predict the next words.
Attention layer

1. The first embedding layer creates word embedding.
2. And we are passing it to GRU layer.
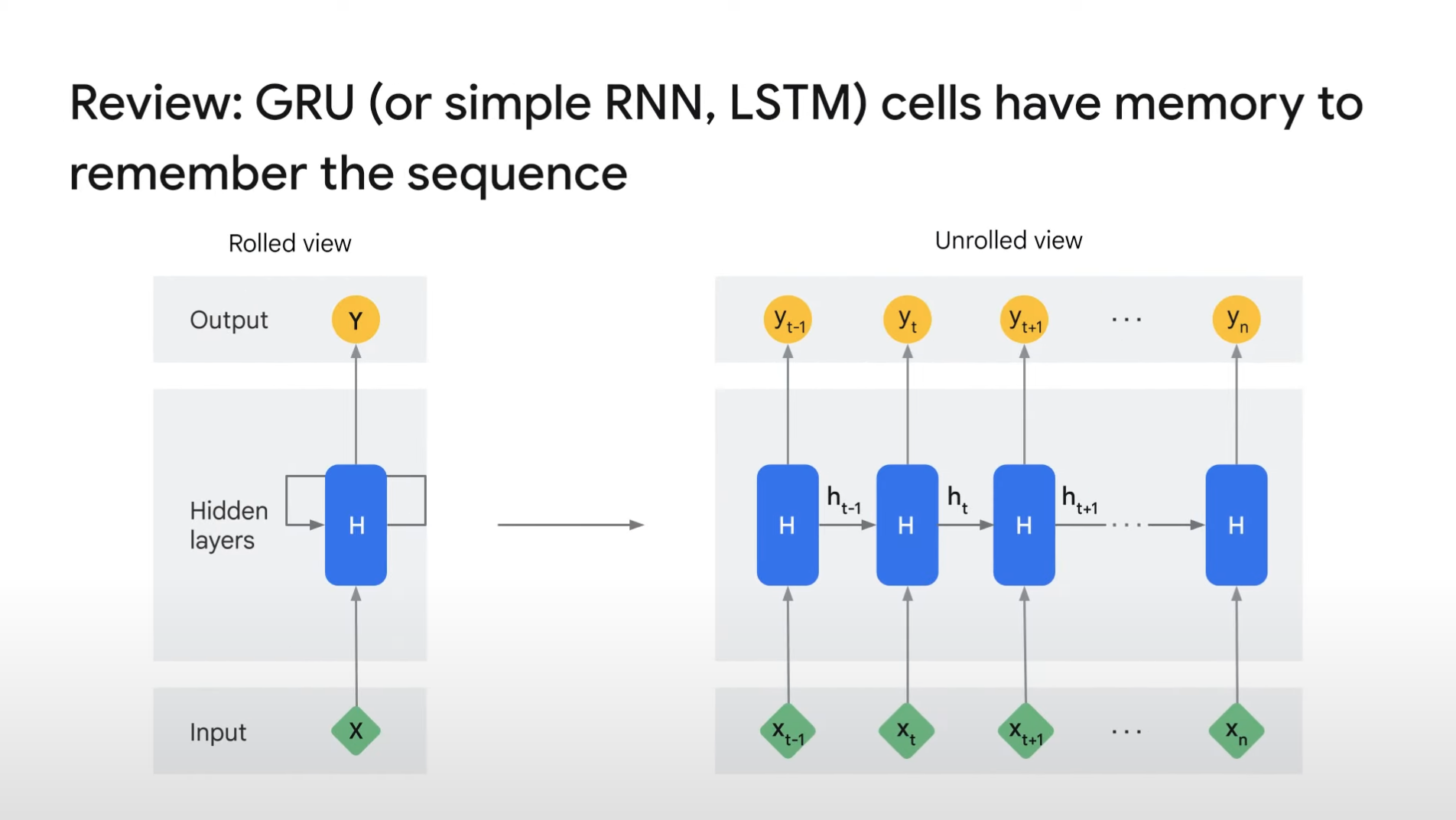
FYI.
- GRU is a variation of Recurrent Neural Network(RNN).
- RNN takes inputs and updates its internal states and generates output.
- By passing sequential data (i.e. text data), it keeps the sequential dependencies from previous iuputs (i.e. previous words).
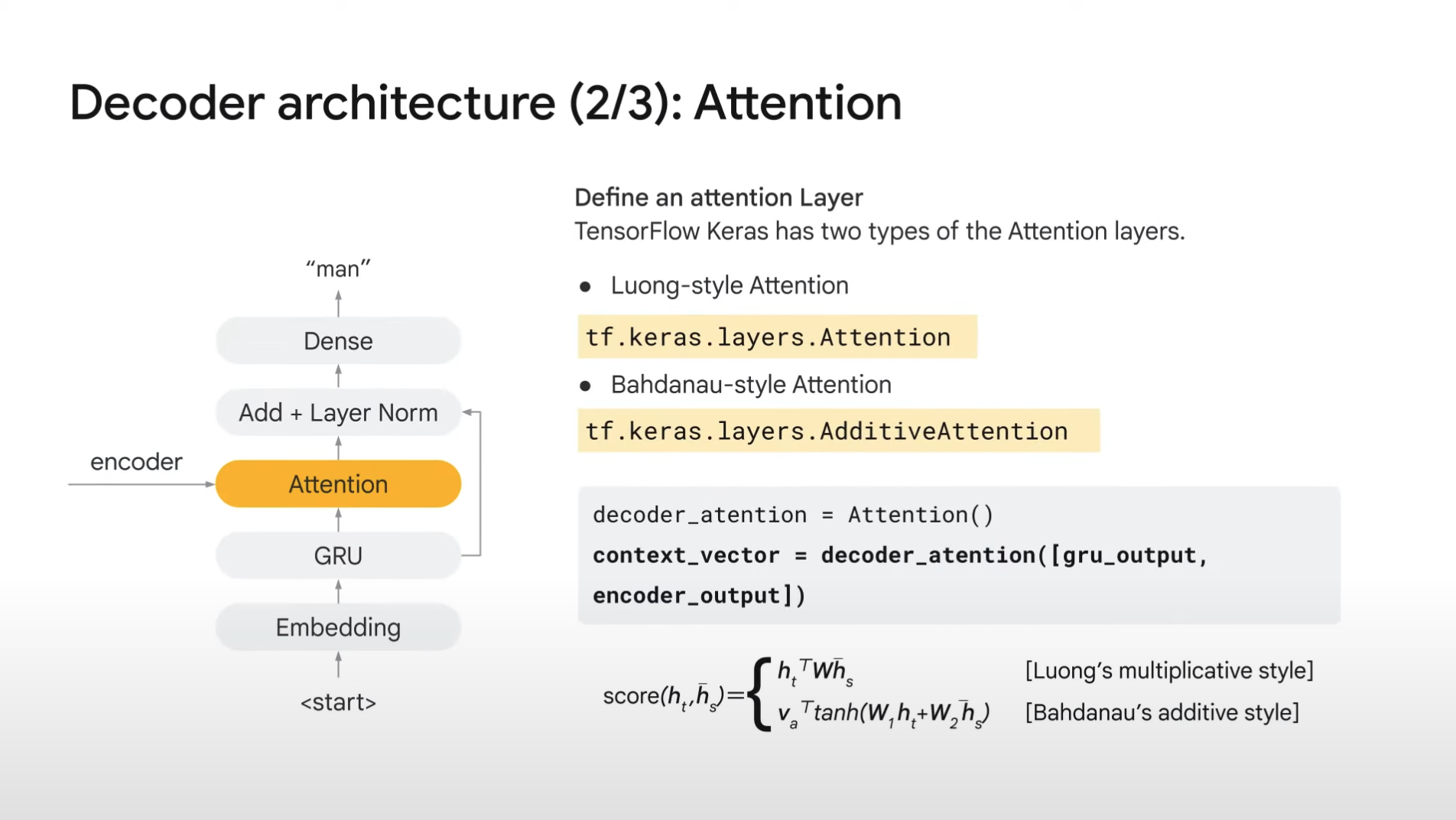
3. The GRU output goes to attention layer, which mixes the information of text and image.
- In TensorFlow Keras, we can use predefined layers in the same way as other layers.
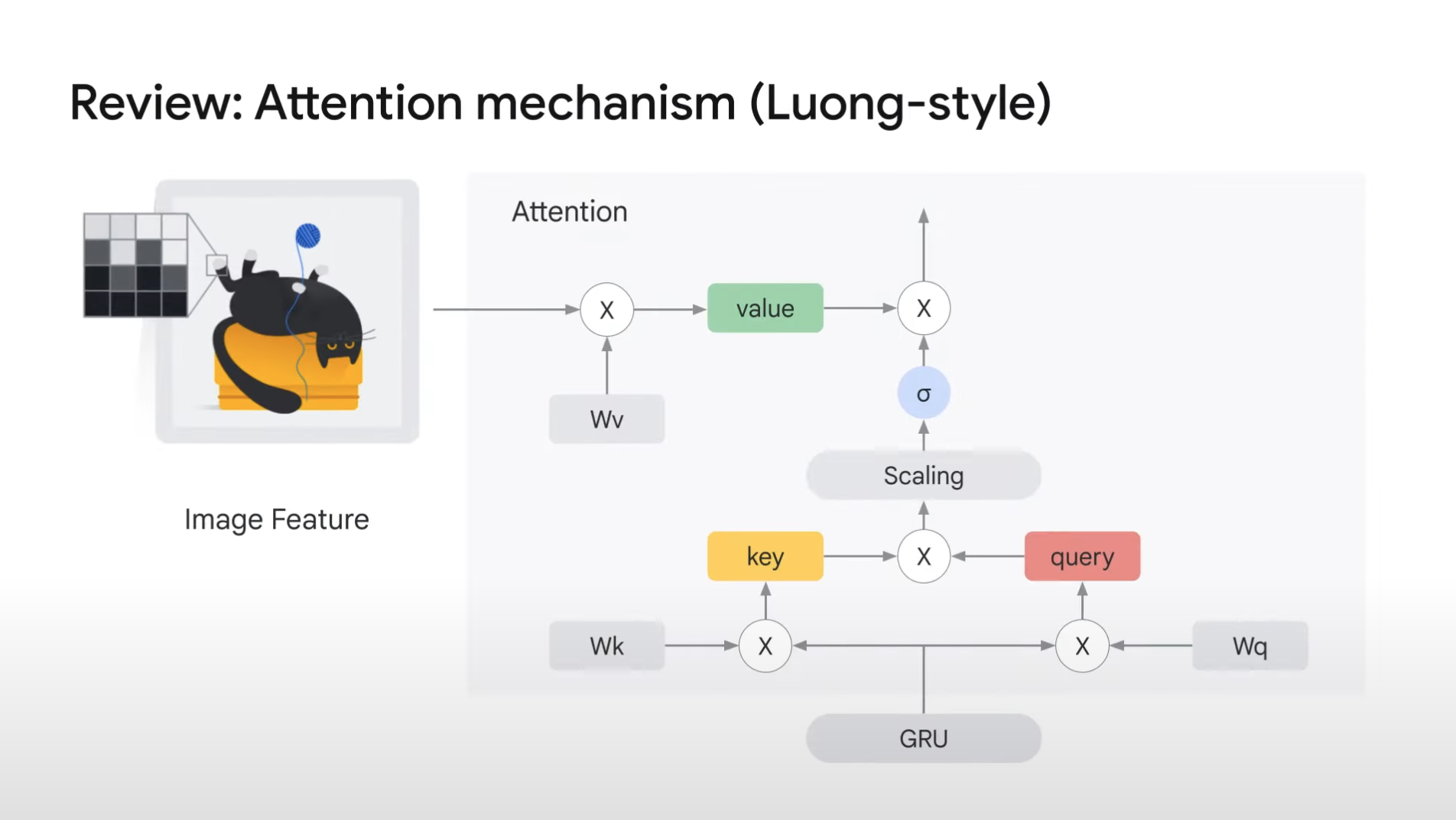
- Inside attention layer, it pays attention to image feature from text data.
- By doing so, it can calculate attention score by mixing both information.

- Attention layer takes two inputs -- ([gru_output, encoder_output])
- gru_output => It is used as attention query and key
- encoder_output => It is used as attention value

- Add layer adds two same-shaped vectors.
- gru_output is passed to attention layer, and to this add layer directly.
- These two flows are eventually merged in this add layer.
- This architecture is called skip connection, which has been a very popular deep neural network design pattern since ResNet.
- It is also called residual connection.
- This skip connection is very useful, especially when you want to design a very deep neural network.
- And it is also using the transformer.
Inference Phase
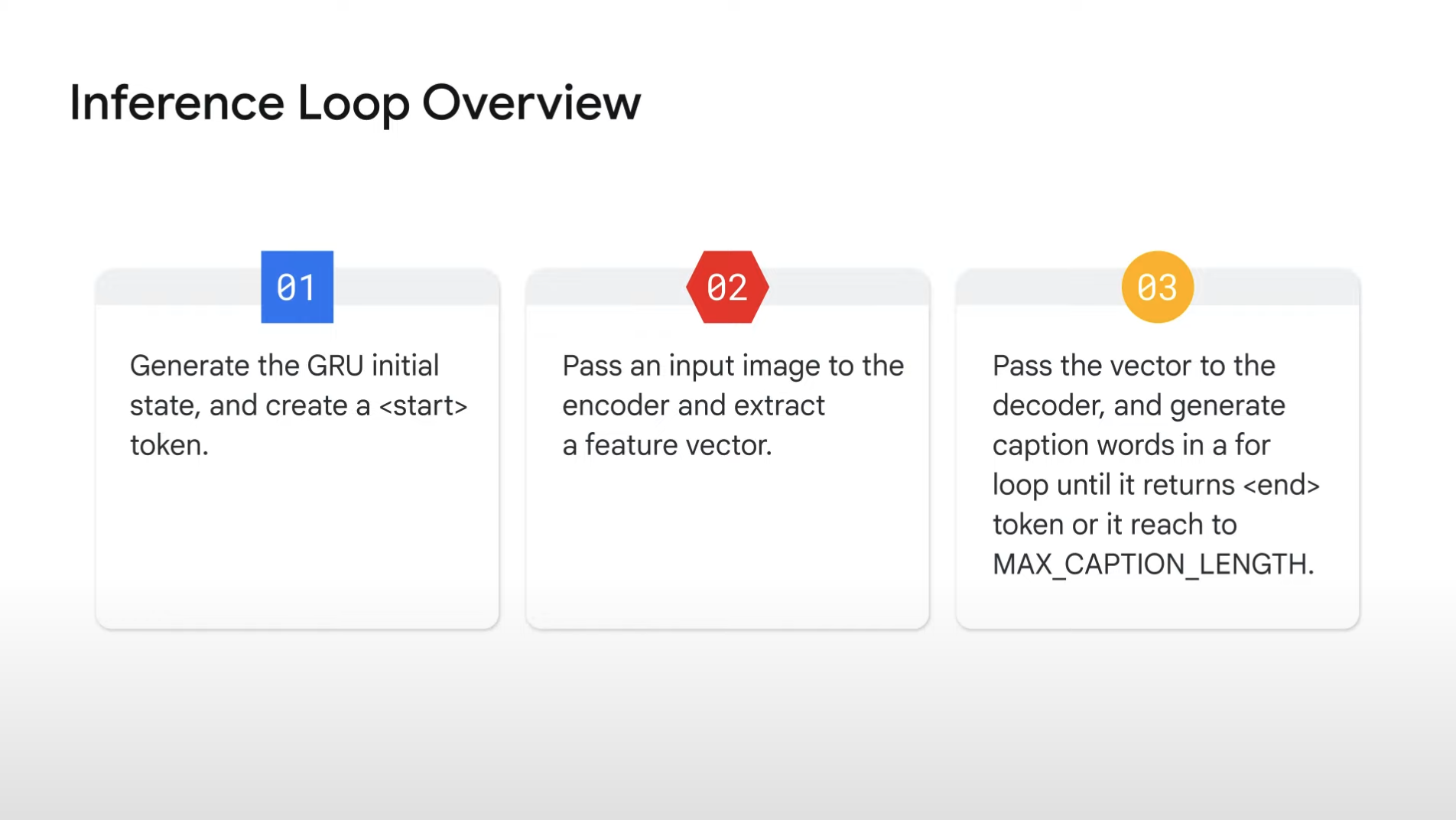
01.
- In training phase, TensorFlow Keras can automatically handle gru_state for each sequence.
- But in this inference phase, since we designed our own custom function, we need to write a logic to deal with it explicitly.
- So at the beginning of each captioning, we explicitly initialize the gru_state with some value.
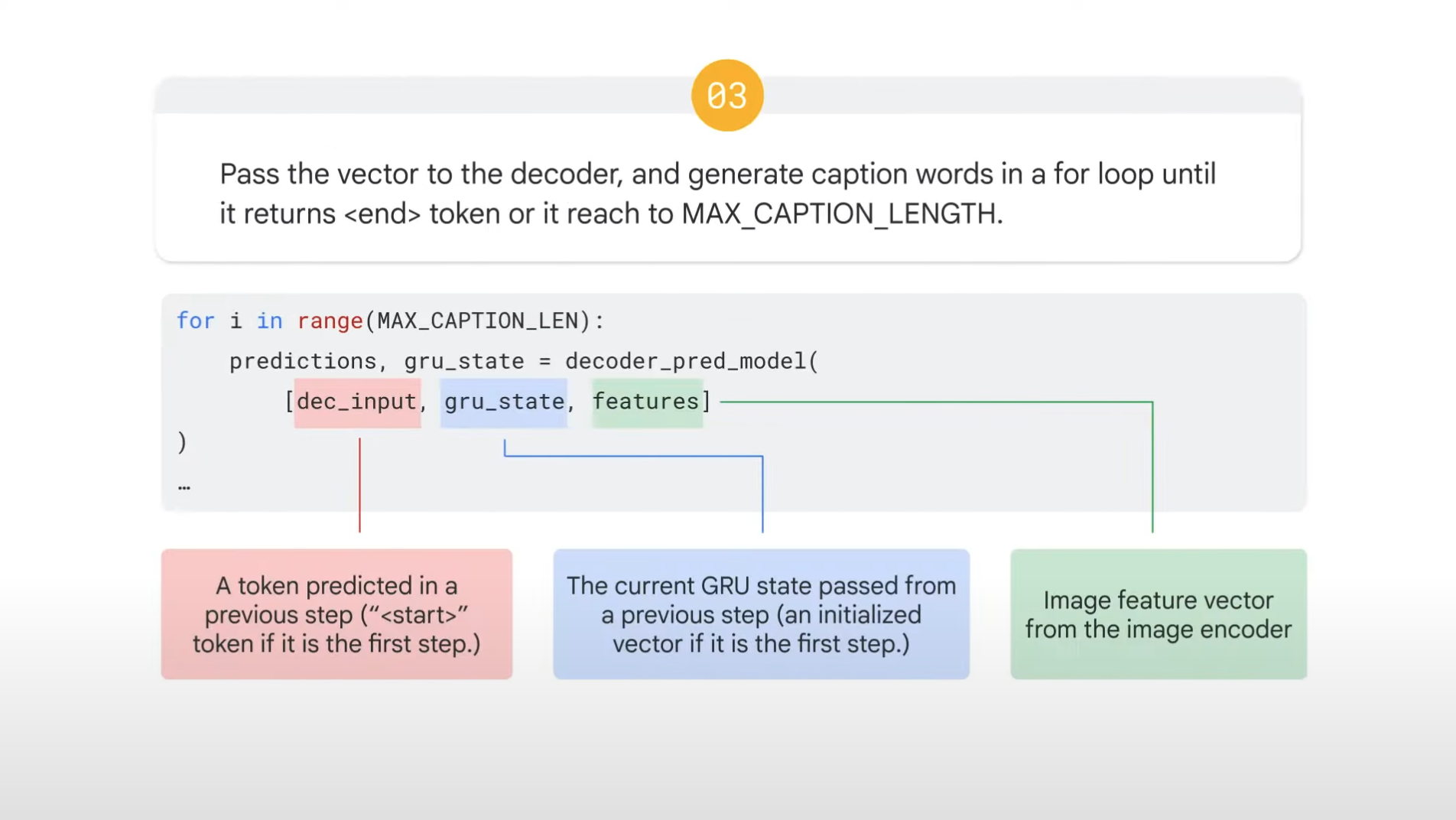
03.
- When our decoder generates this token, we can finish this for loop.
- Or you can go out of the loop when the length of the caption reaches some number, MAX_CAPTION_LENGTH.
Code
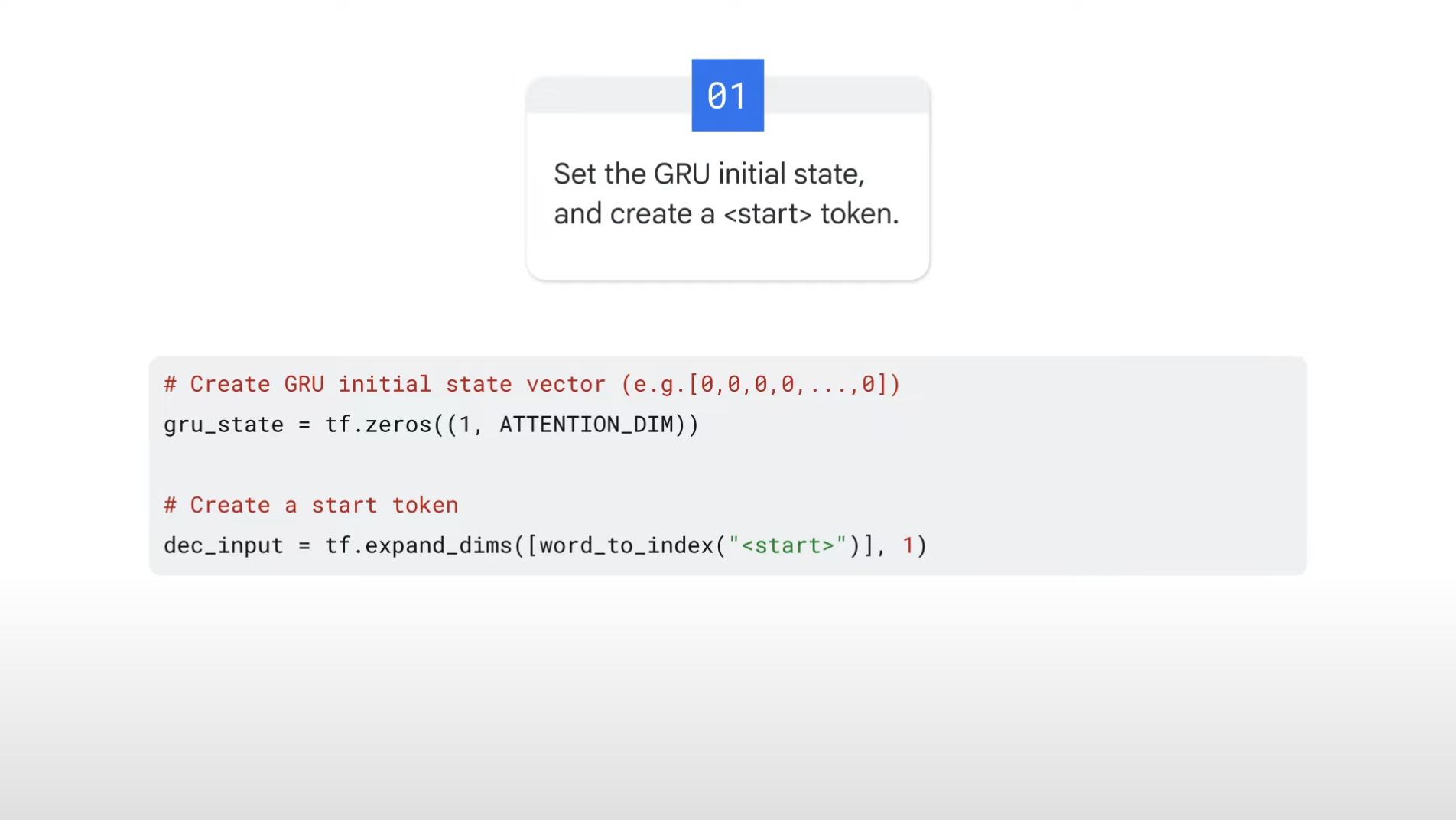
- We initialize two things -- gru_state, <start> token

- We process the input image and pass it to the encoder we train.
Github Repo for Image Captioning with Visual Attention Image Captioning with Visual Attention: