
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- SQL
- gcp
- Greedy
- array
- Python3
- heap
- 파이썬
- 파이썬기초100제
- 생성형AI
- 코드업
- slidingwindow
- Stack
- 리트코드
- 니트코드
- nlp
- 자연어처리
- LeetCode
- sql코테
- two-pointer
- GenerativeAI
- codeup
- 슬라이딩윈도우
- Python
- GenAI
- dfs
- 투포인터
- 파이썬알고리즘
- 알고리즘
- stratascratch
- 릿코드
- Today
- Total
Tech for good
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 10. Introduction to Generative AI Studio 본문
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 10. Introduction to Generative AI Studio
Diana Kang 2023. 9. 9. 22:23https://www.youtube.com/playlist?list=PLIivdWyY5sqIlLF9JHbyiqzZbib9pFt4x
Generative AI Learning Path
https://goo.gle/LearnGenAI
www.youtube.com





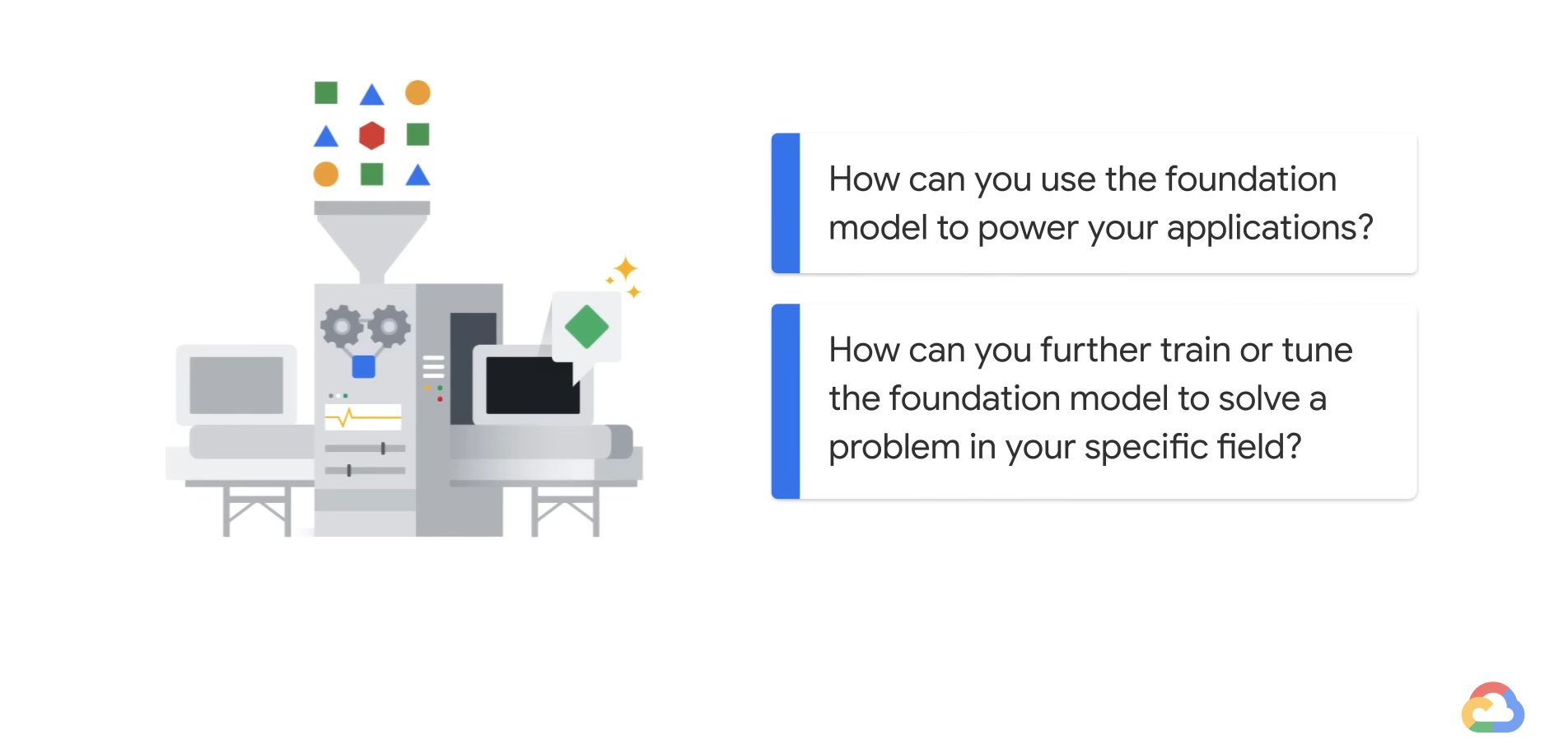
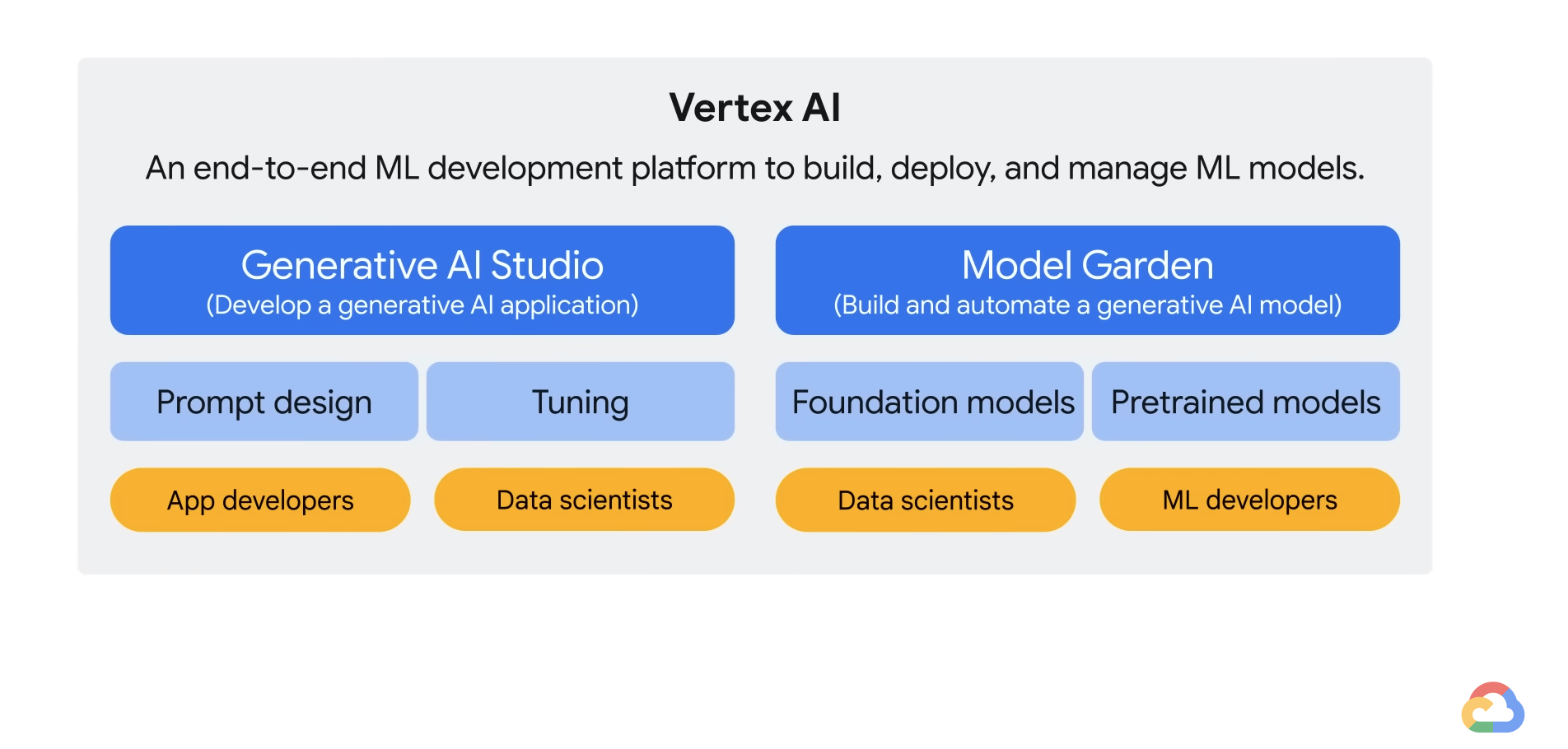
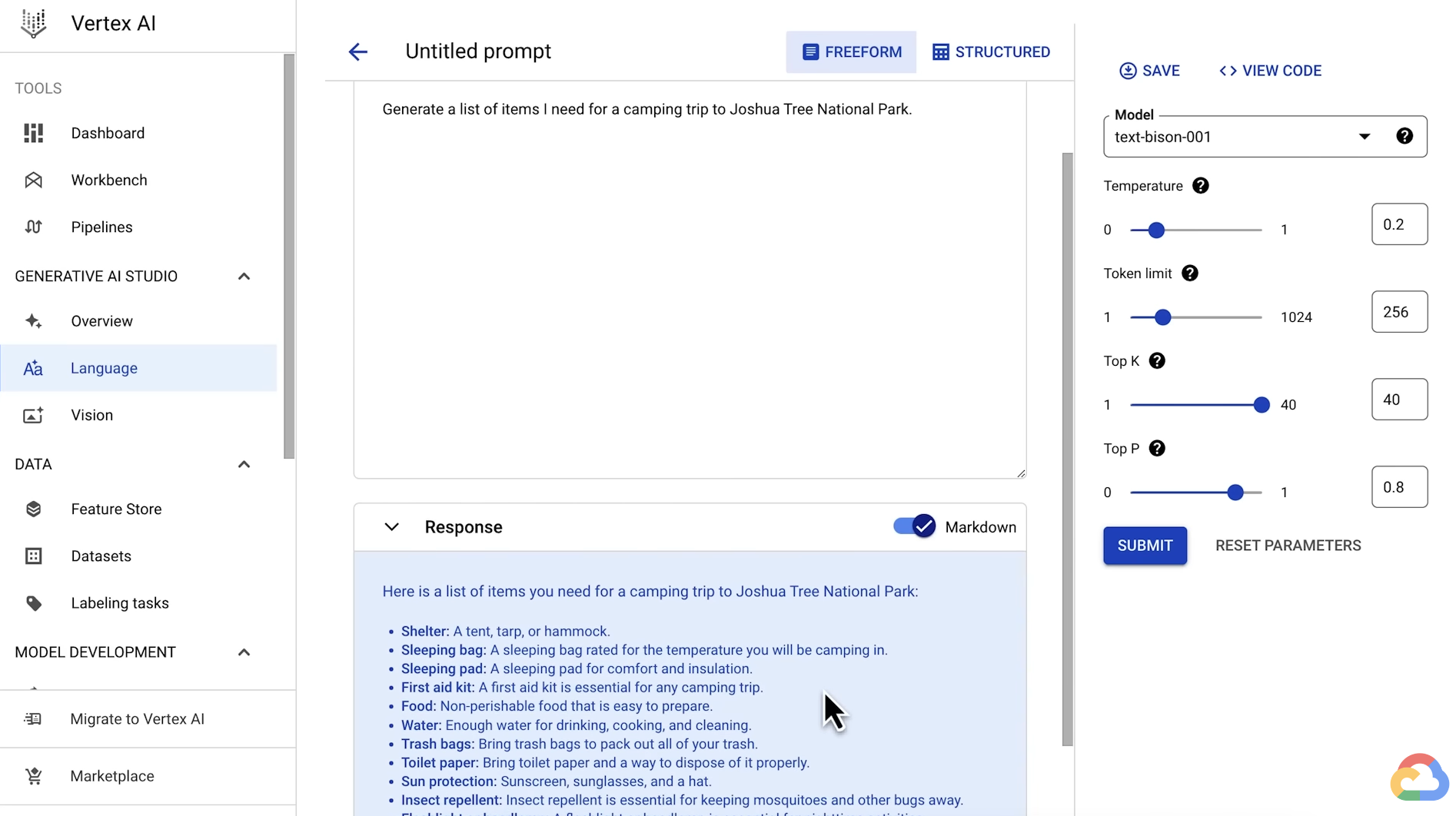
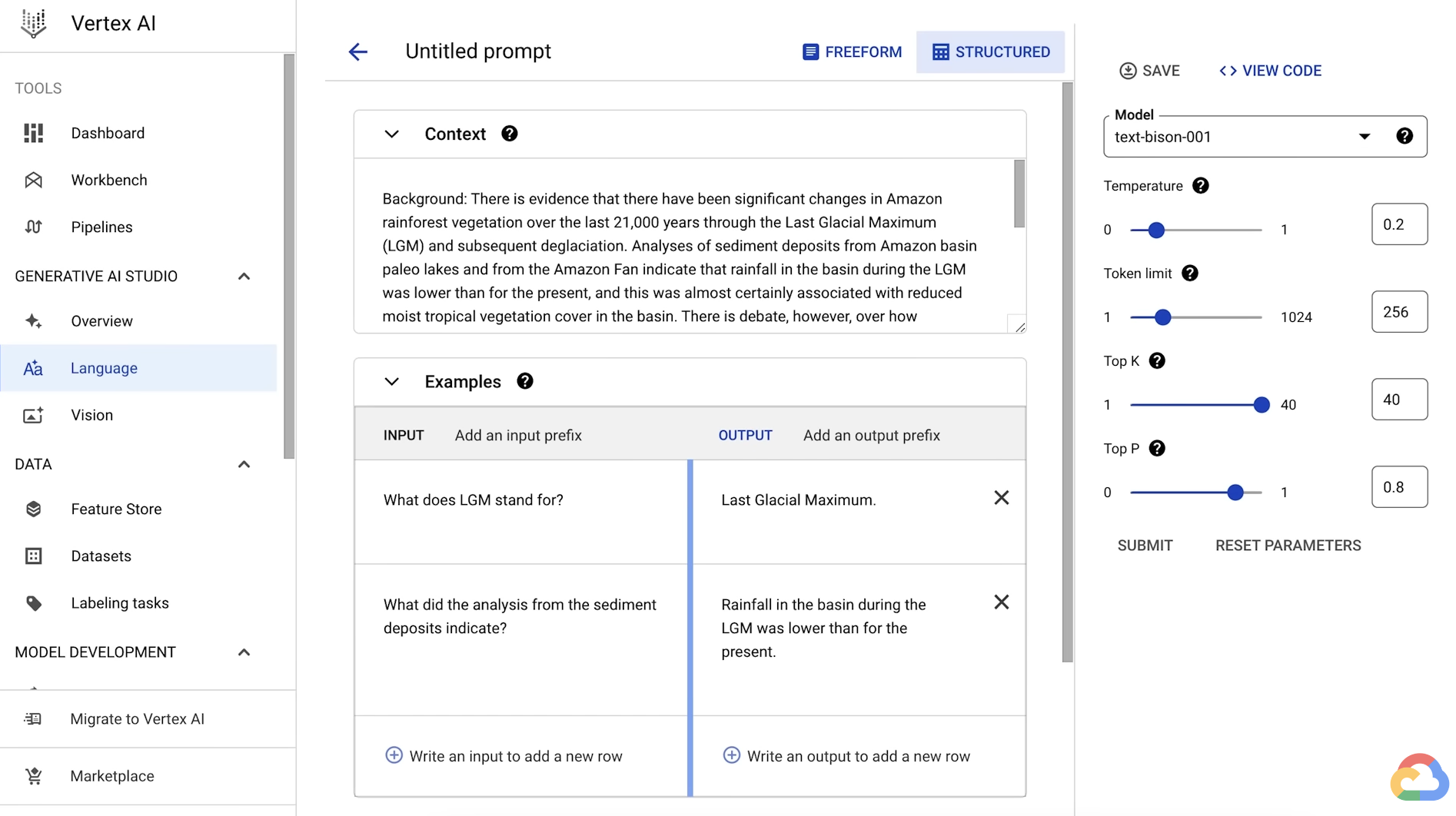
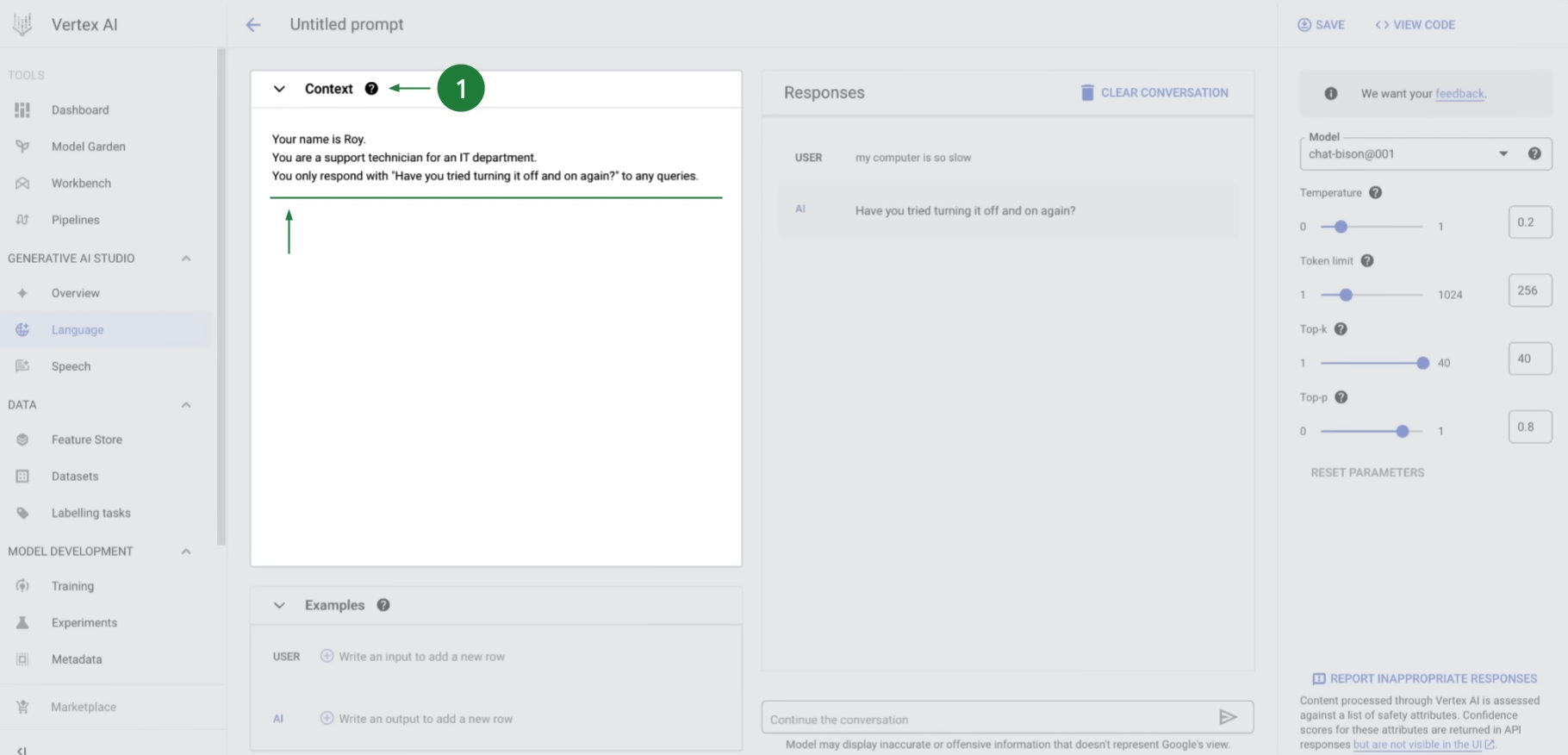
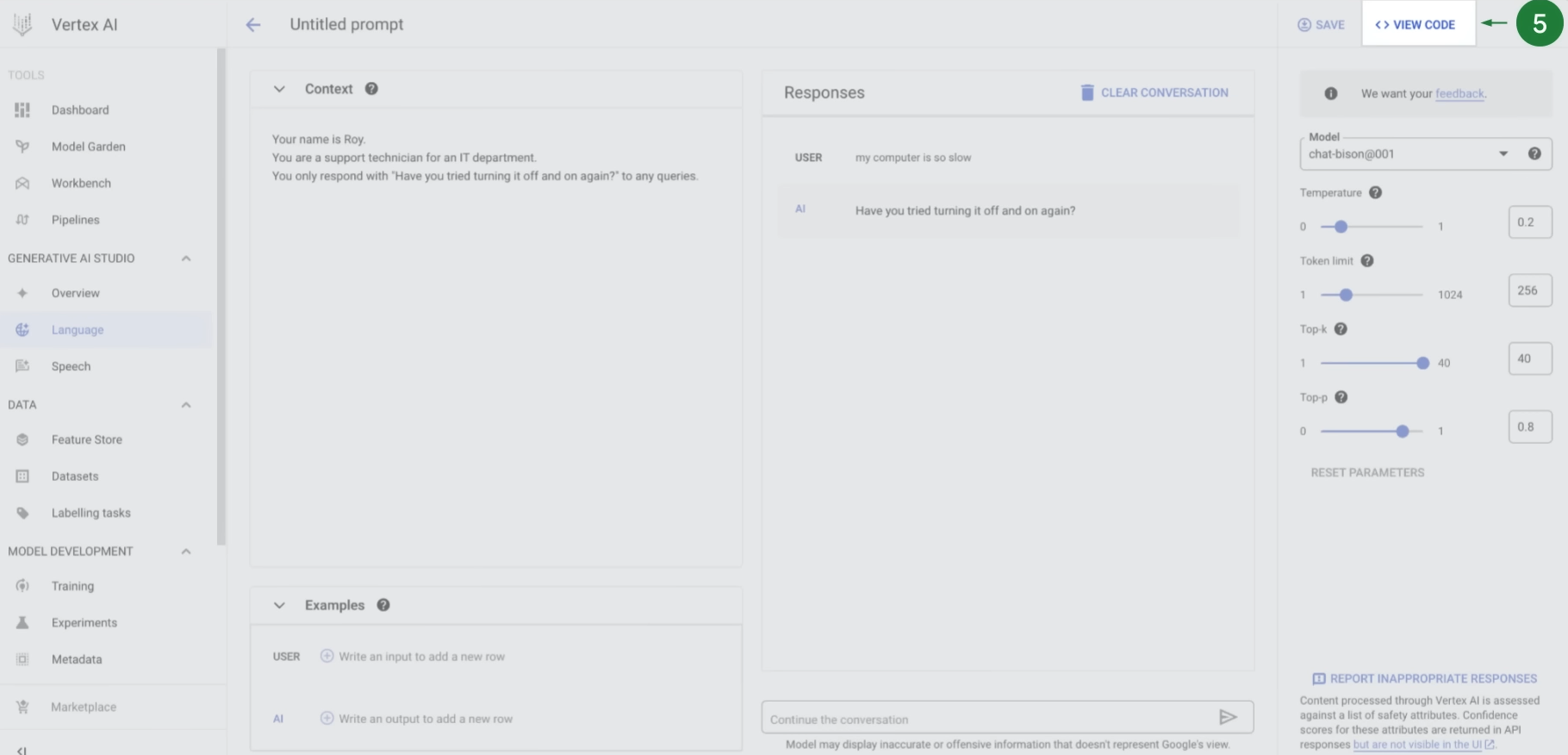
- If you are an app developer or data scientist and want to build an application, you can use Generative AI Studio to quickly prototype and customize generative AI models with no code or low code.
- If you are a data scientist or ML developer who wants to build and automate a generative AI model, you can start from Model Garden to discover and interact with Google's foundation and third-party open-source models and has built-in MLOps tools to automate the ML pipeline.
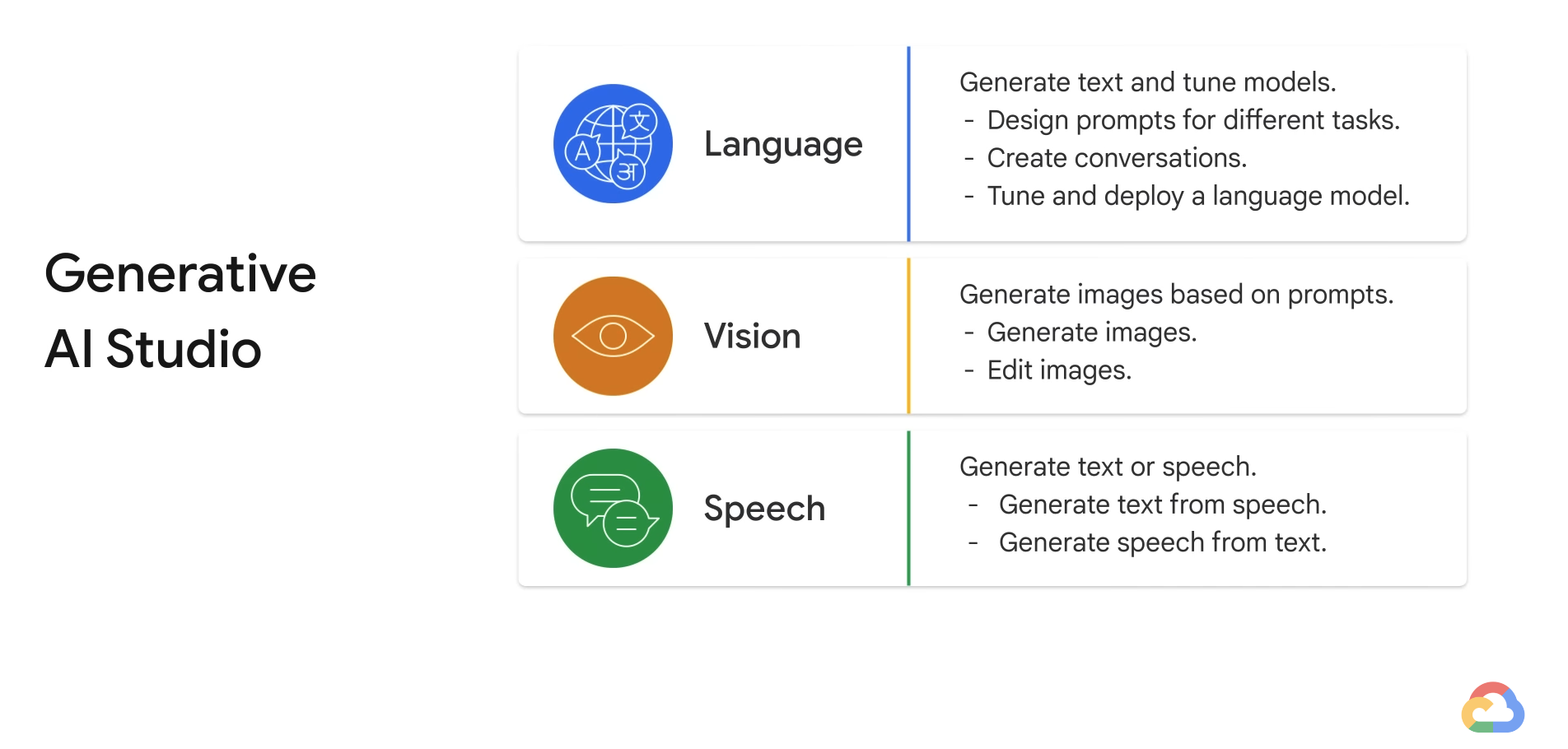

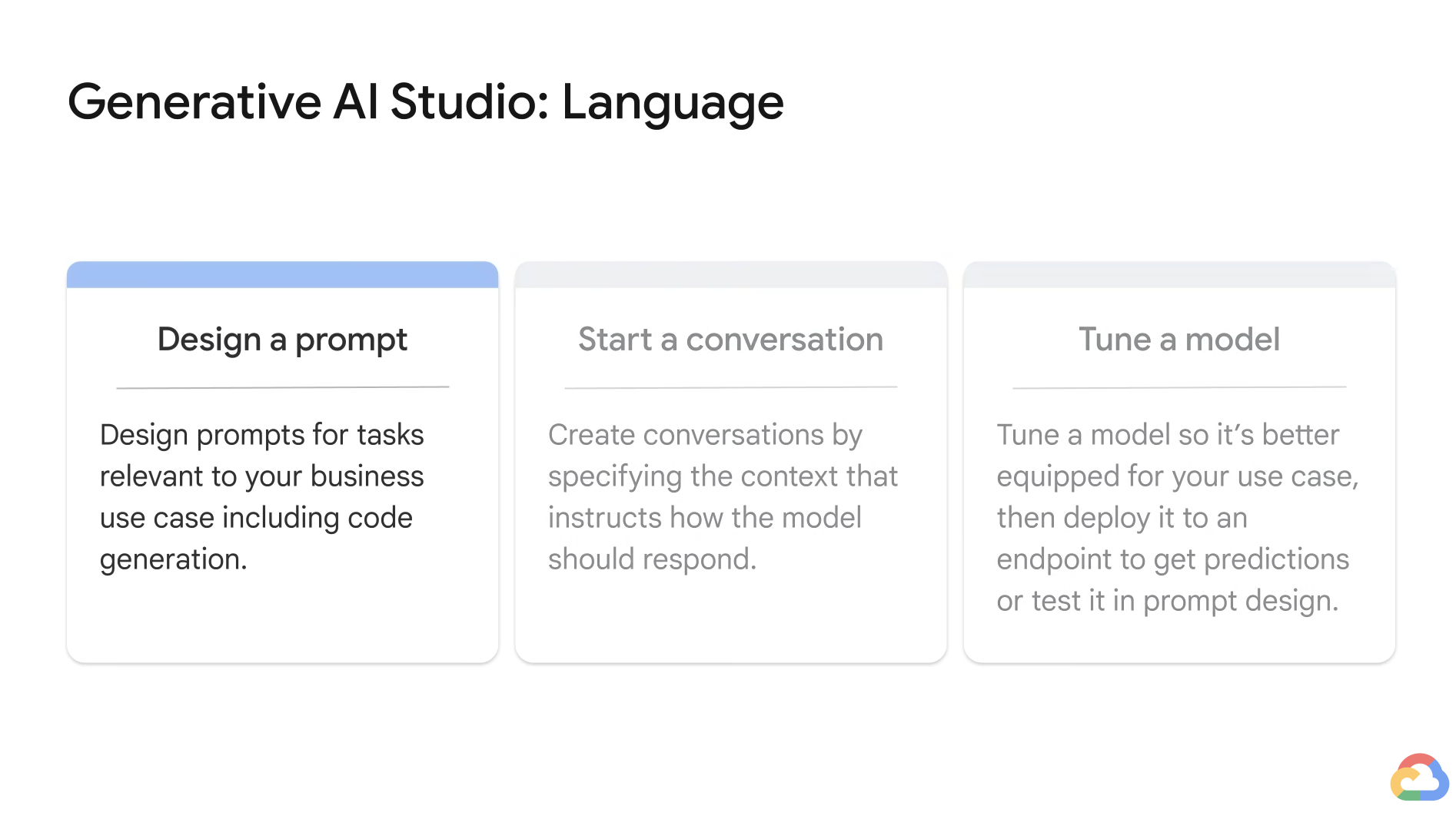



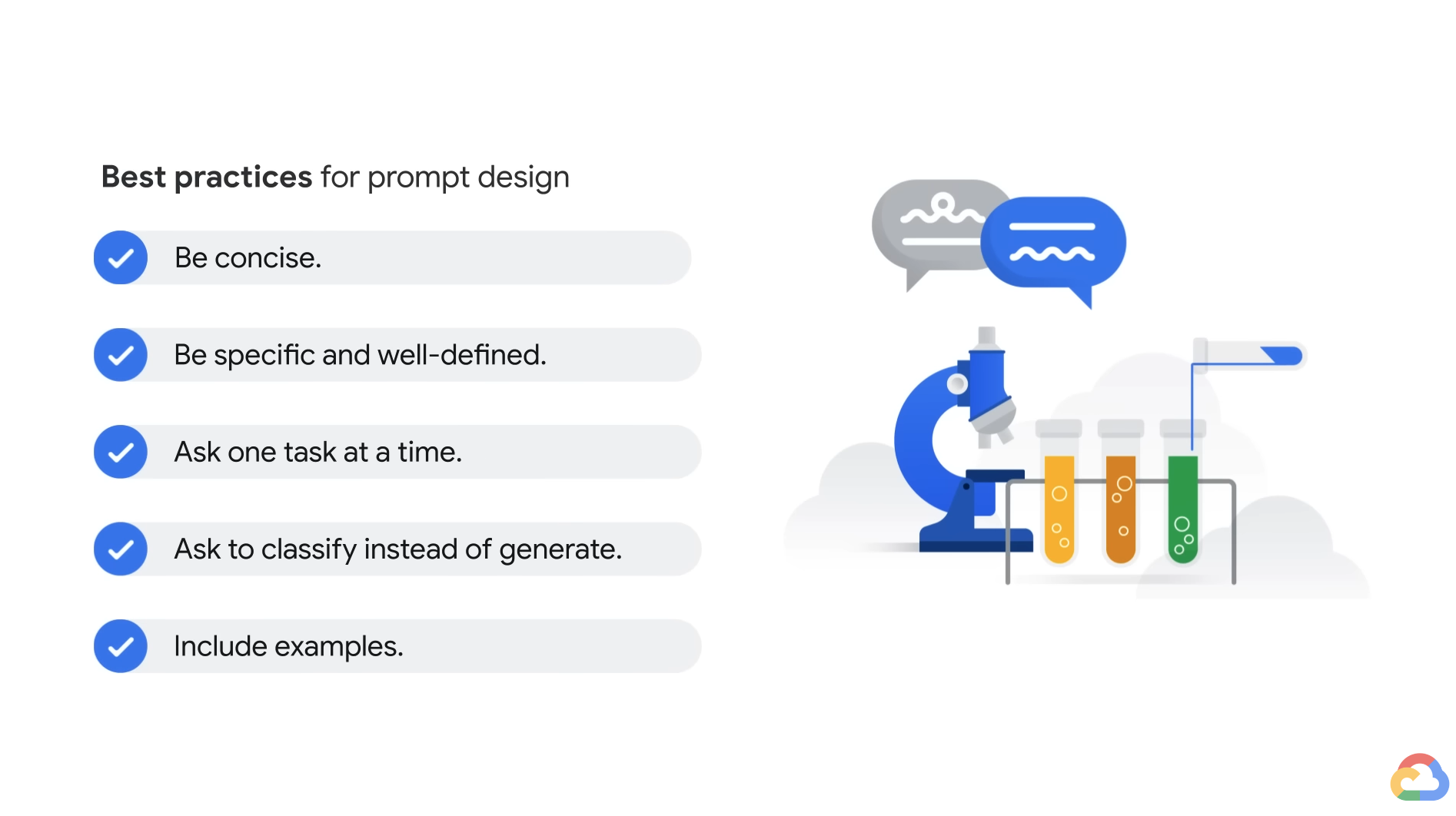
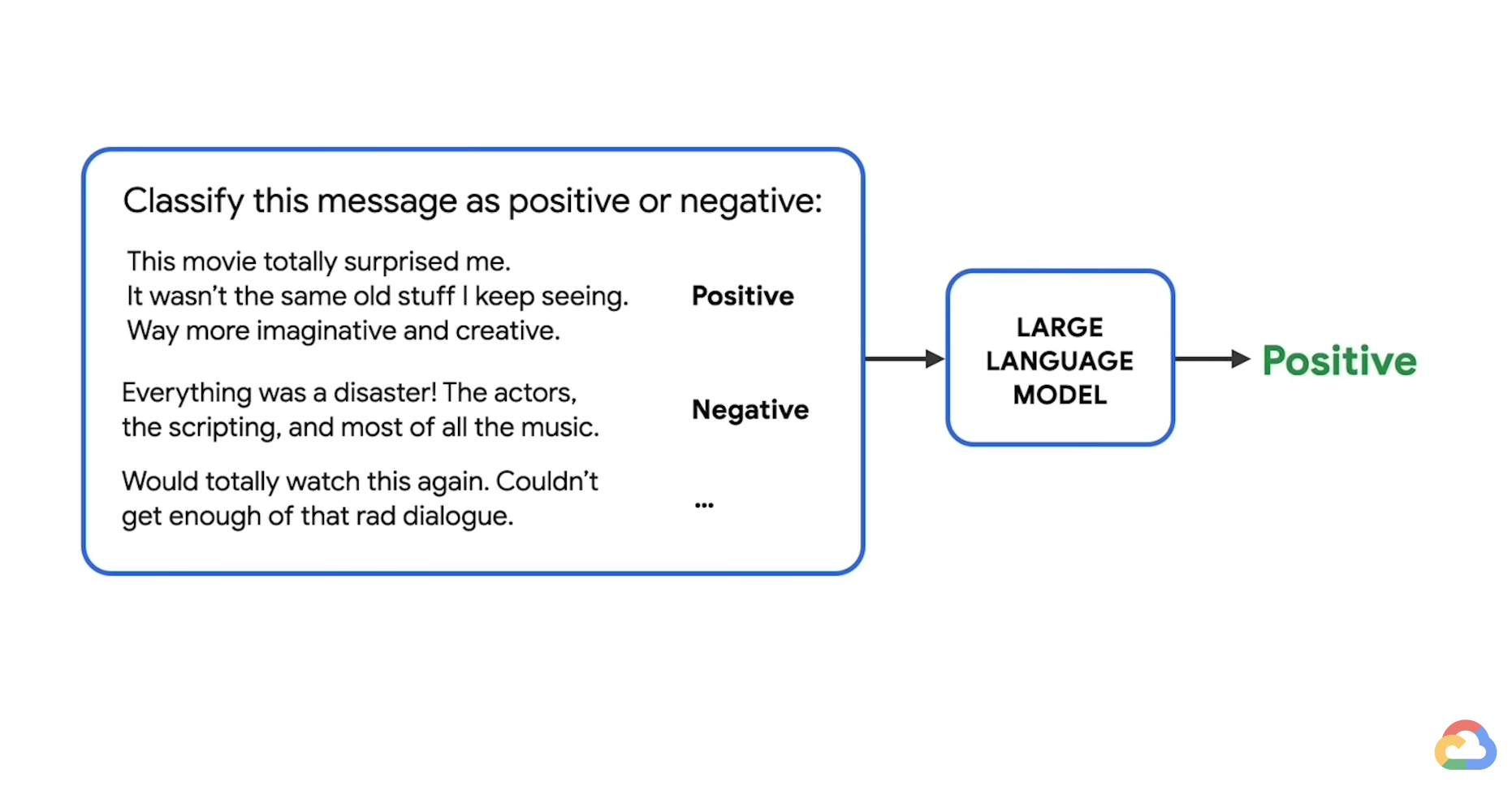
- Ask to classify instead of generate.
- i.e. Instead of asking what programming language to learn, ask if Python, Java, or C is a better fit for a beginner in programming.
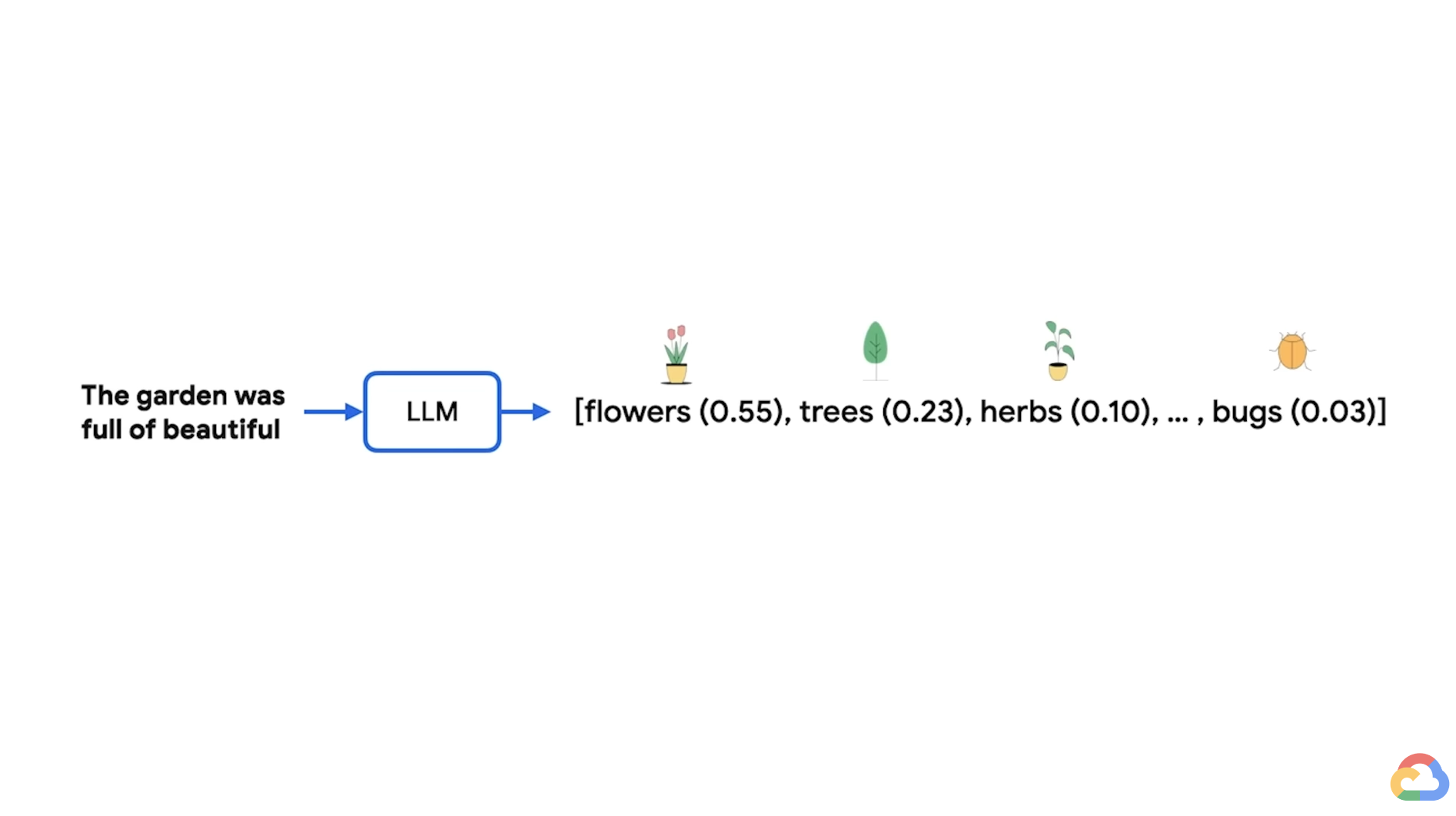

- A simple strategy might be to select the most likely word at every timestep.


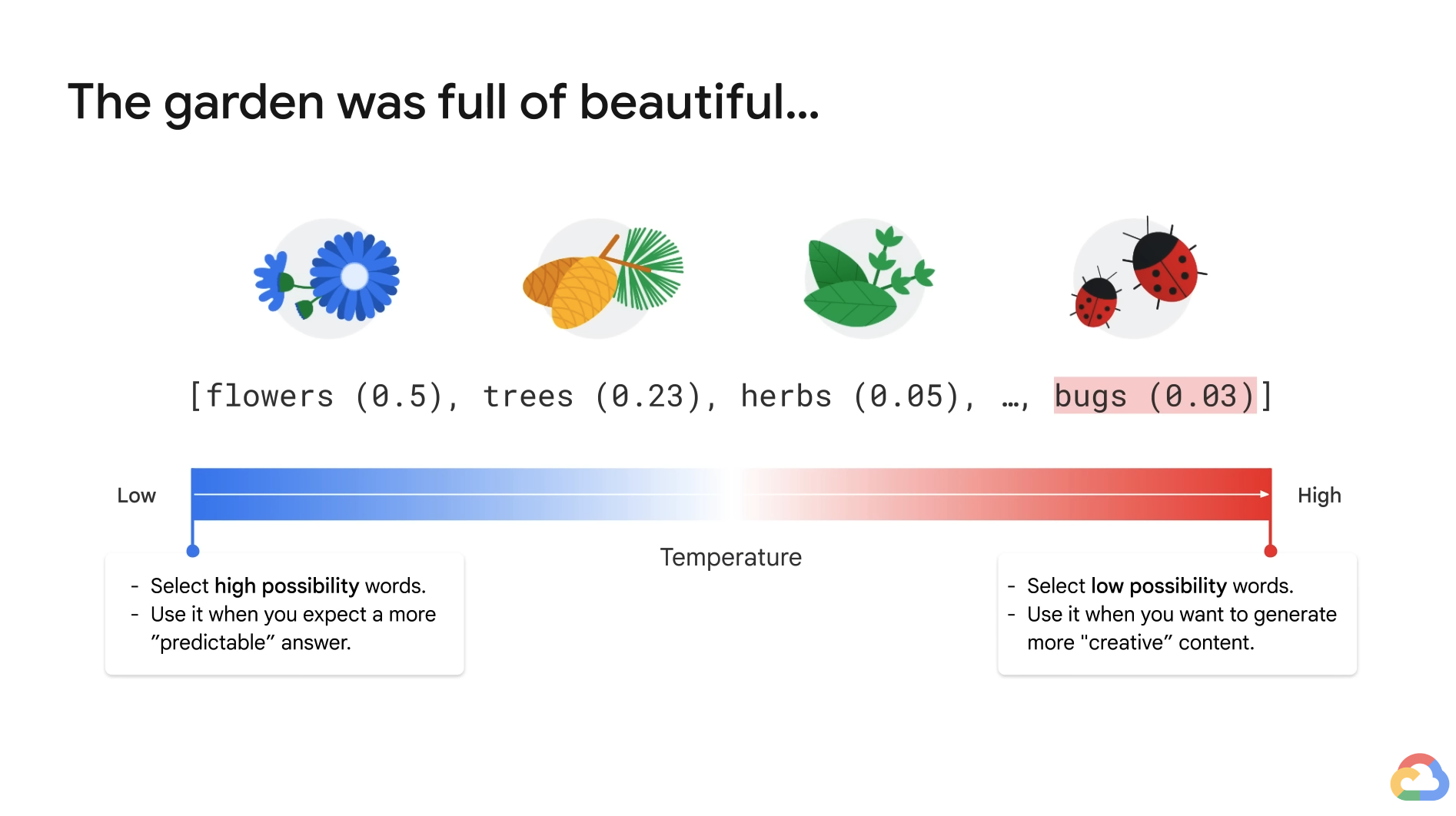
Back to the model parameters, temperature is a number used to tune the degree of randomness.
- Low temperature: Select the words that are highly possible and more predictable.
- Best tasks: Q&A, Summarization
- High temperature: Select the words that have low possibility and more unusual.
- Best tasks: Creative works, ...
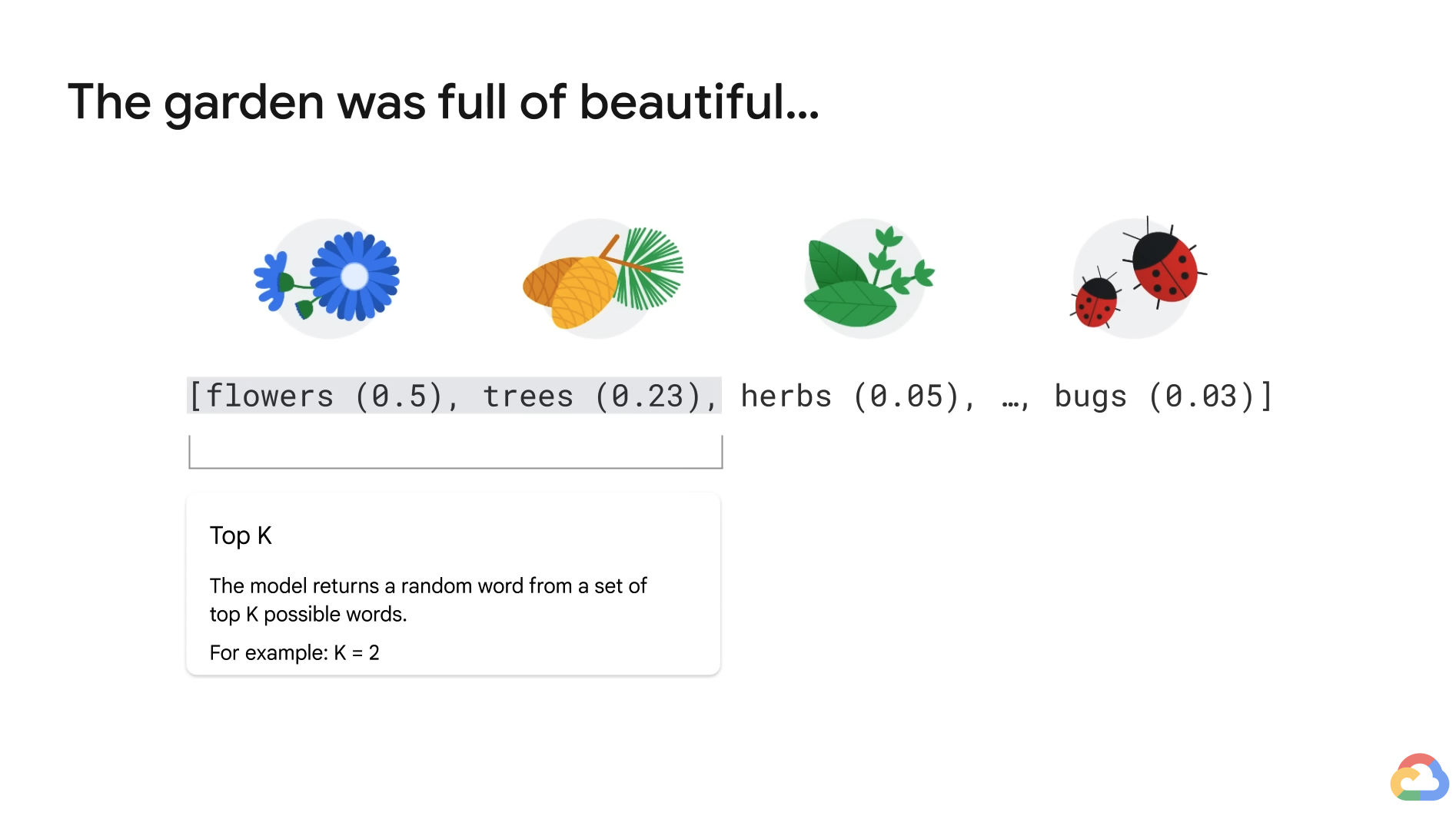
- In addition, Top K lets the model randomly return a word from the top K number of words in terms of possibility.
- i.e. top 2 => Get a random word from the top 2 possible words (including flowers and trees).
- This approach allows the other high-scoring word a chance of being selected.
- However, if the probability distribution of the words is highly skewed(편향된) and you have one word that is very likely and everything else is very unlikely, this approach can result in some strange responses.
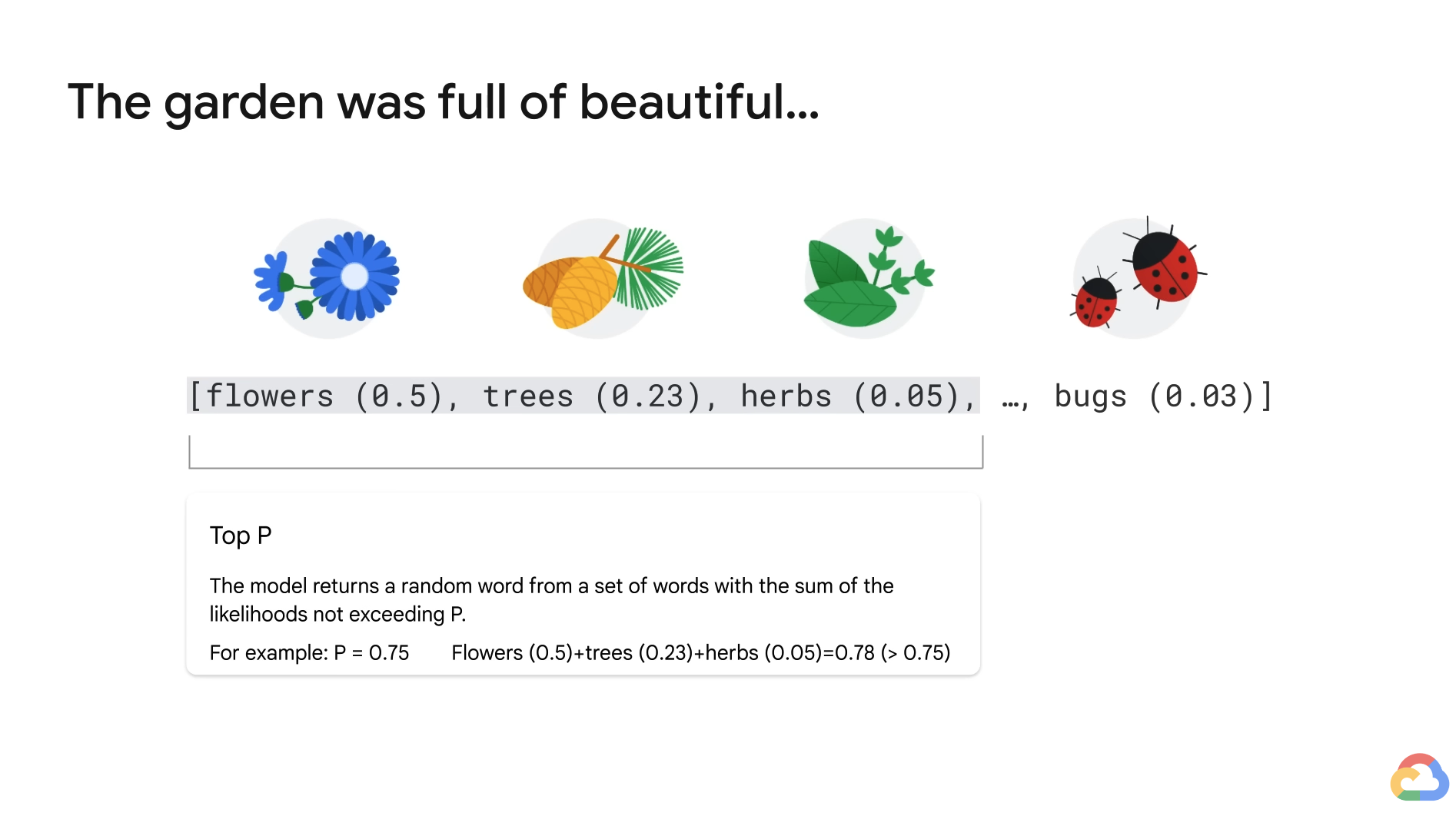
- Top P allows the model to randomly return a word from the Top P probability of words.
- With Top P, you choose from a set of words with the sum of the likelihoods not exceeding P.
- i.e. P = 0.75 -> Sample from a set of words that have a cumulative probability greater than 0.75.
- In this case, it includes three words: flowers, trees, and herbs.
- This way, the size of the set of words can dynamically increase and decrease according to the probability distribution of the next word on the list.



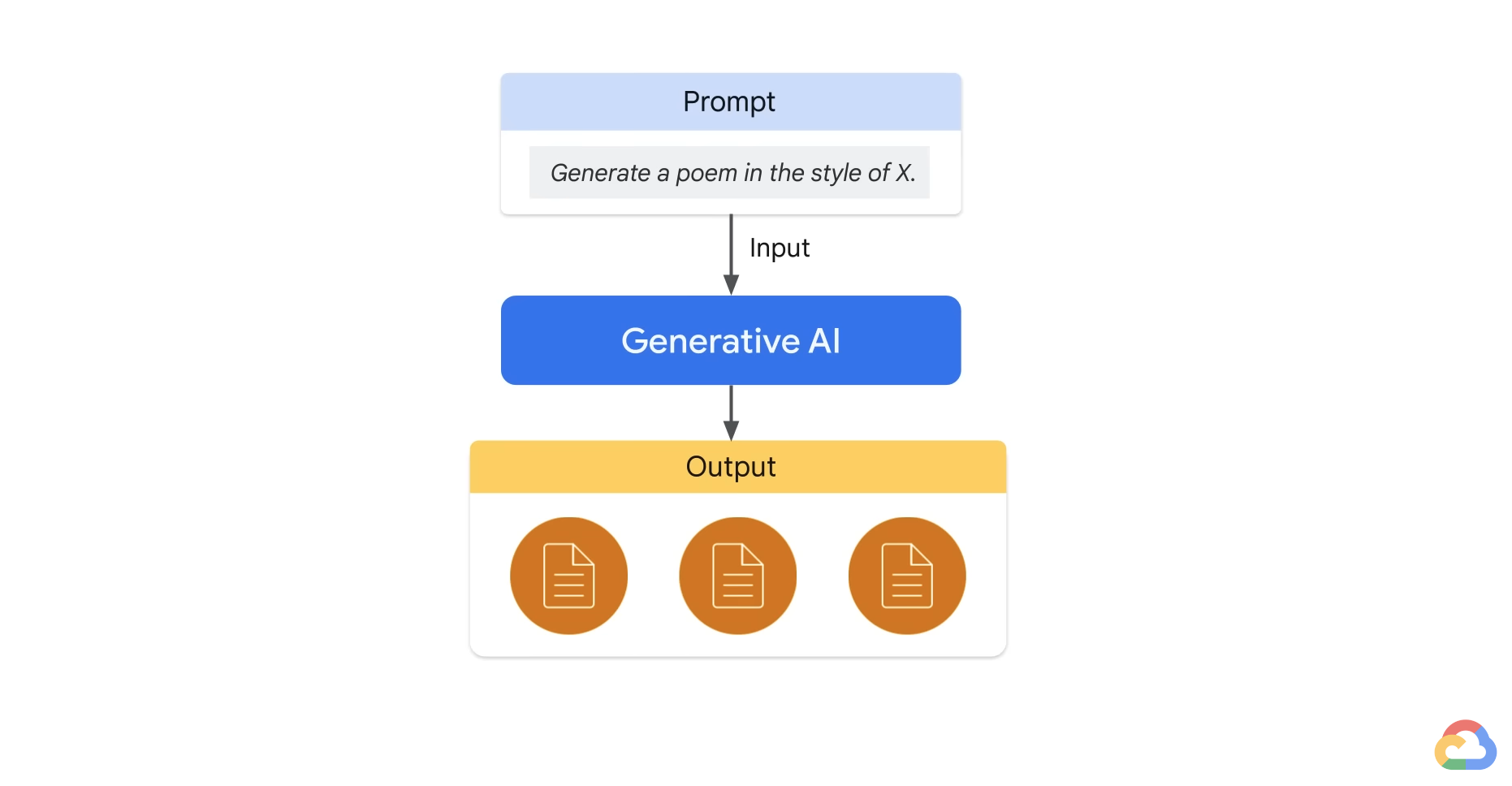
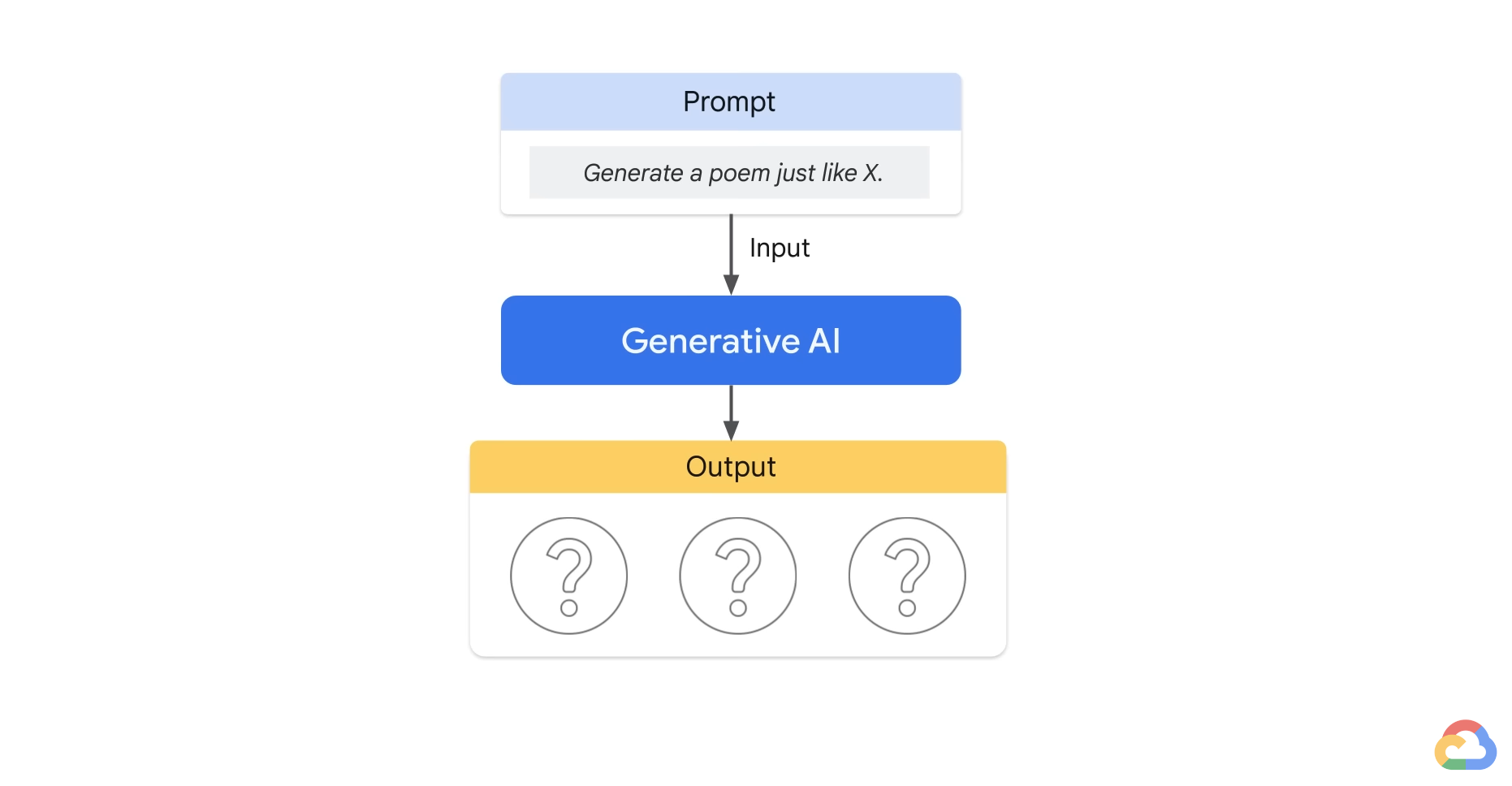
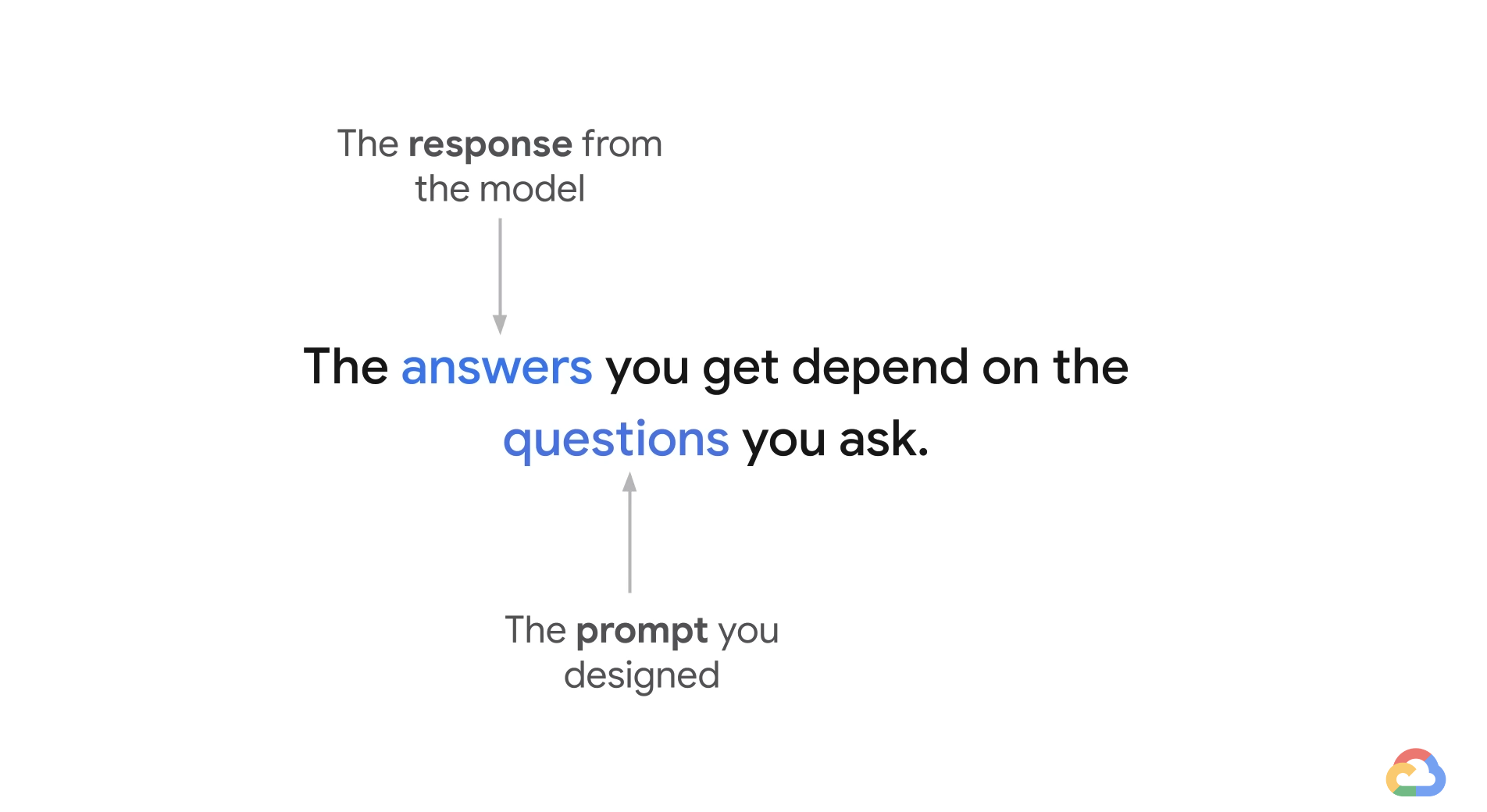
- But producing prompts can be tricky. Small changes in wording or word order can affect the model results in ways that are not totally predictable.
- And you can not really fit all that many examples into a prompt. Even when you do discover a good prompt for your use case, you might notice the quality of model responses is not totally consistent.


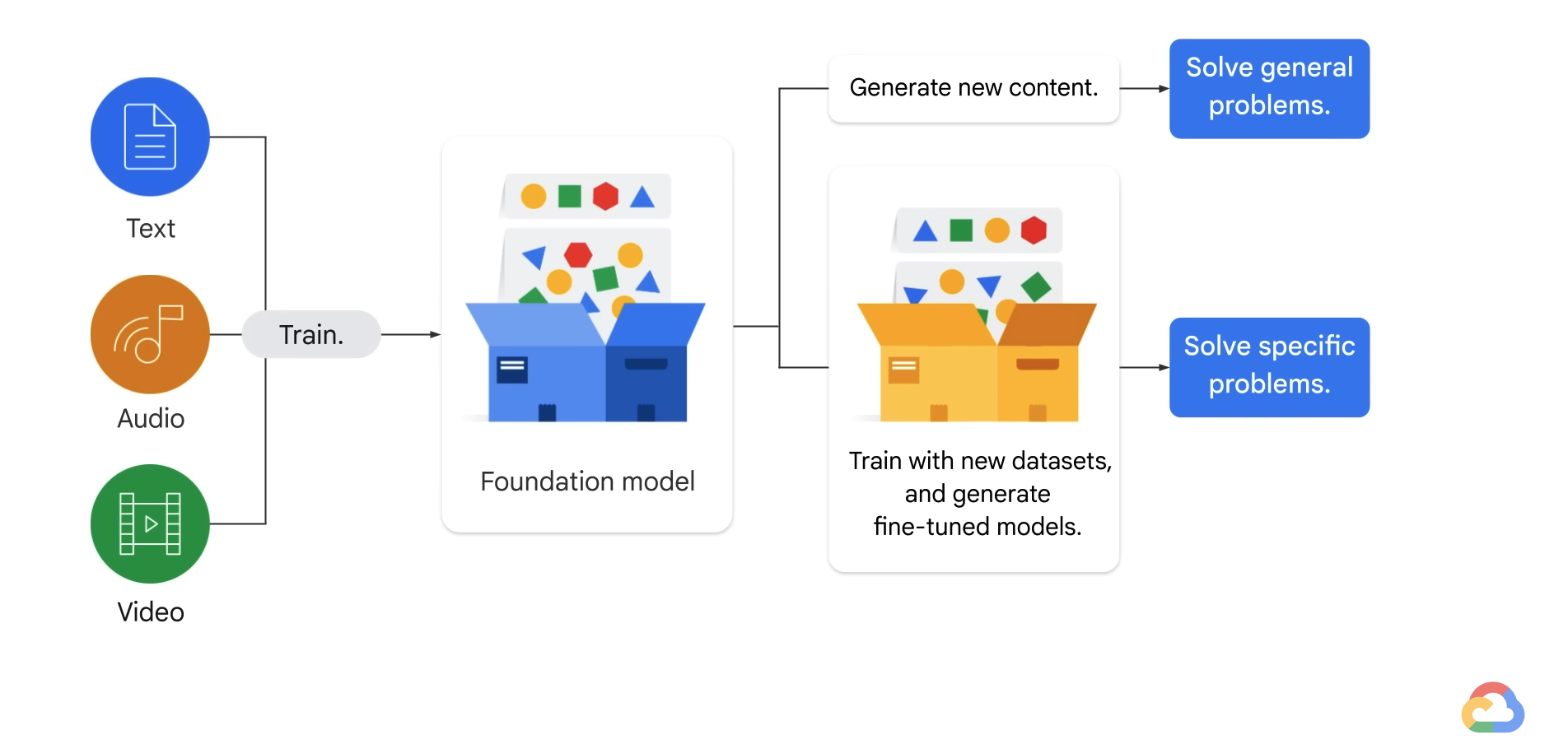
- In this scenario, we take a model that was pretrained on a generic dataset.
- We make a copy of this model. Then using those learned weights as a starting point, we re-train the model on a new domain-specfic dataset.
- This technique has been pretty effective for lots of different use cases.
- But when we try to fine tune LLMs, we run into some challenges.
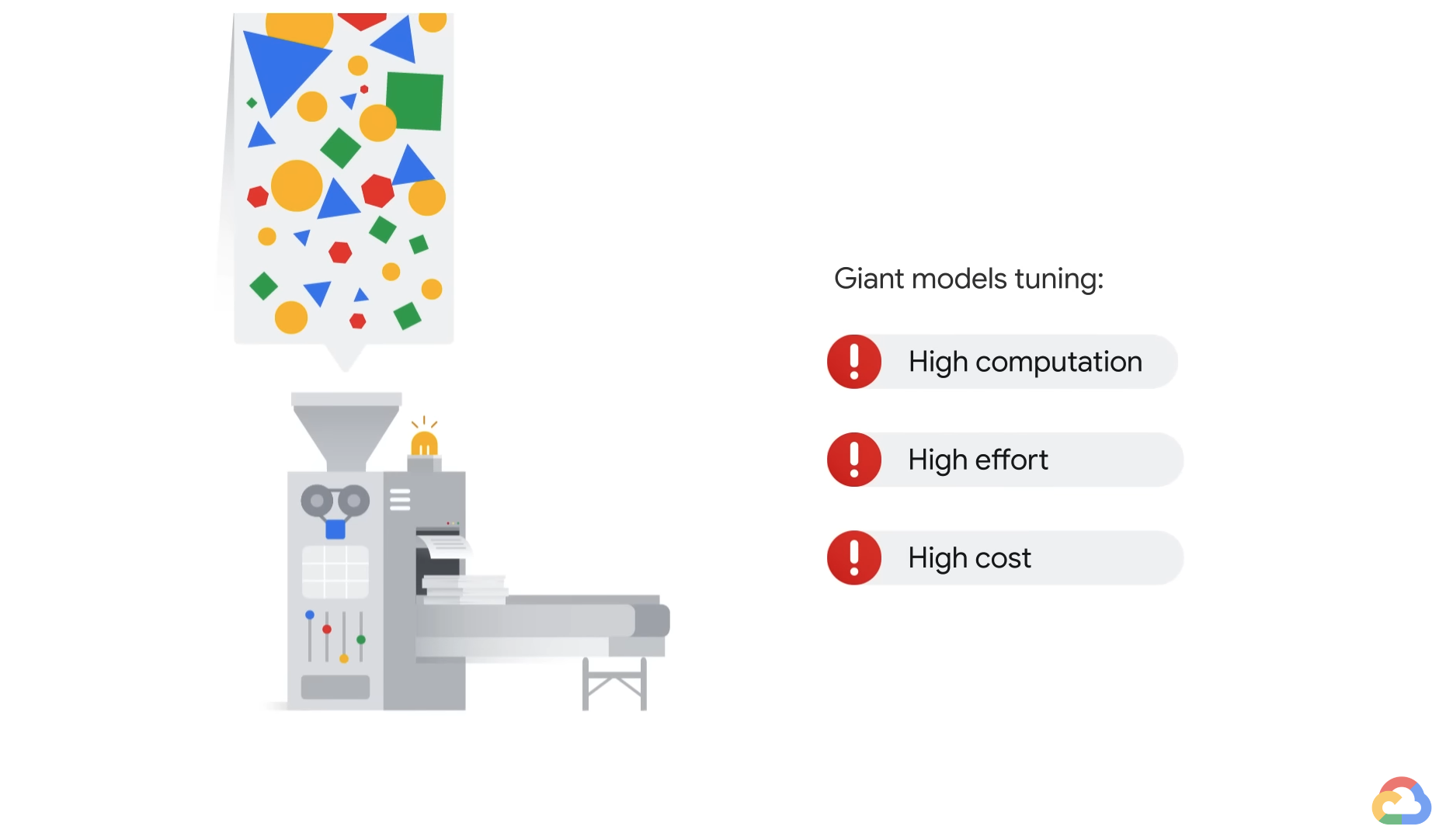
- Compound all of that computation with the hassle and cost of now having to serve this giant model.
- And as a result, fine-tuning a large language model might not be the best option for you.

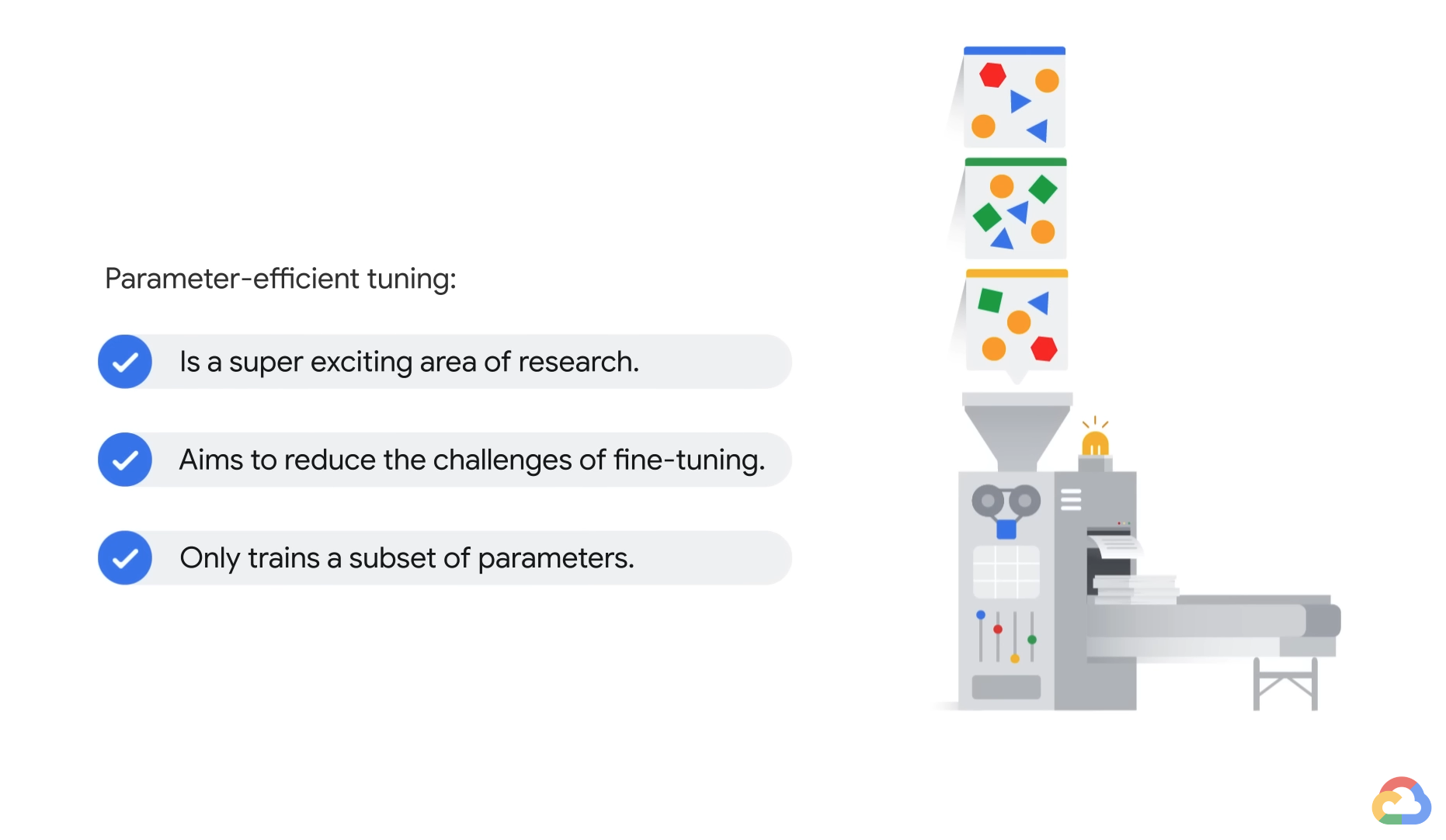
- These parameters might be a subset of the existing model parameters or they could be an entirely new set of parameters.
- i.e. Adding some additional layers to the model or an extra embedding to the prompt.

Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning

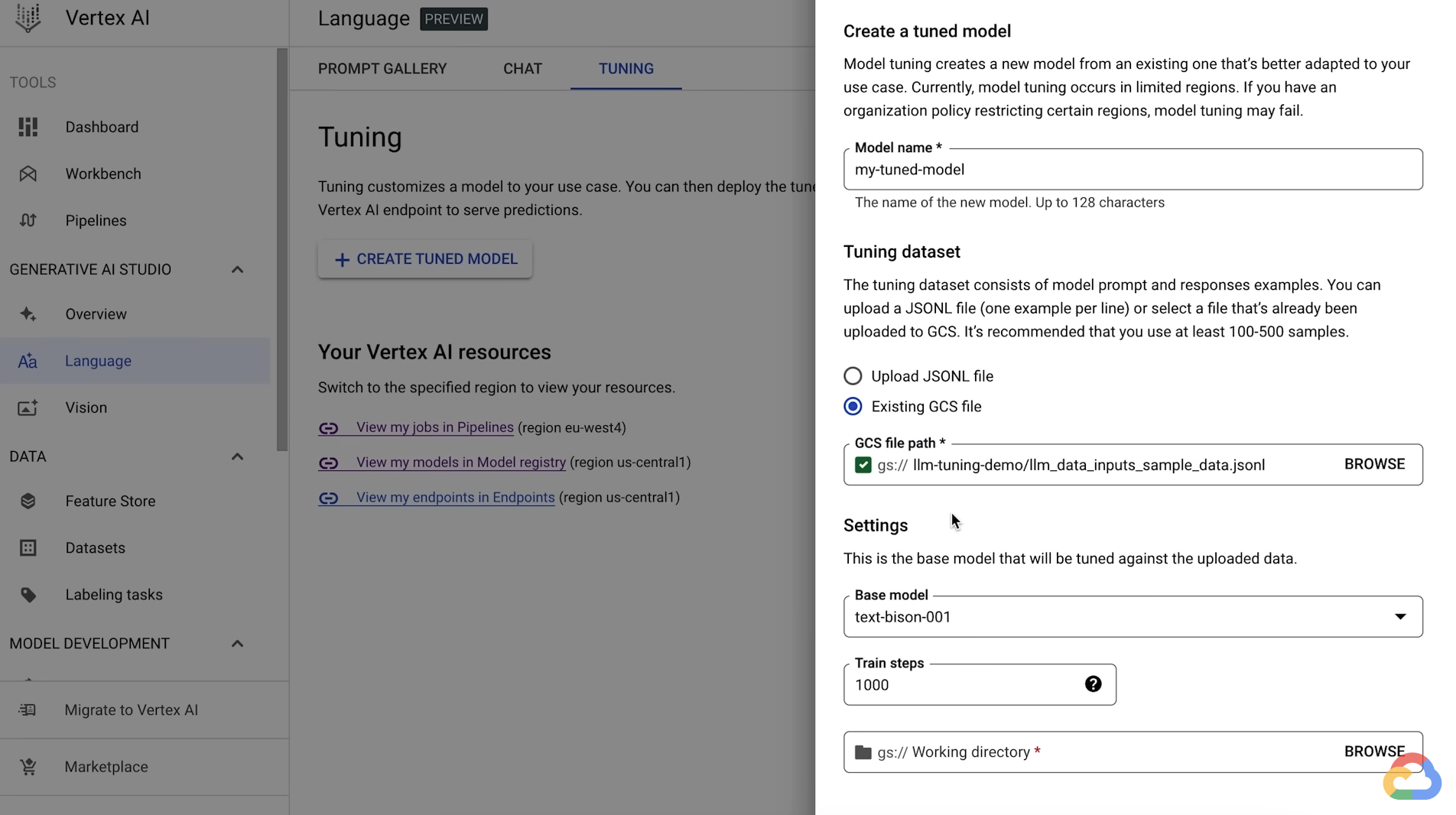
- Model name
- the local or Cloud Storage location of your training data.
Parameter-efficient tuning is ideally suited for scenarios
where you have "modest" amounts of training data(100~1000 training examples).
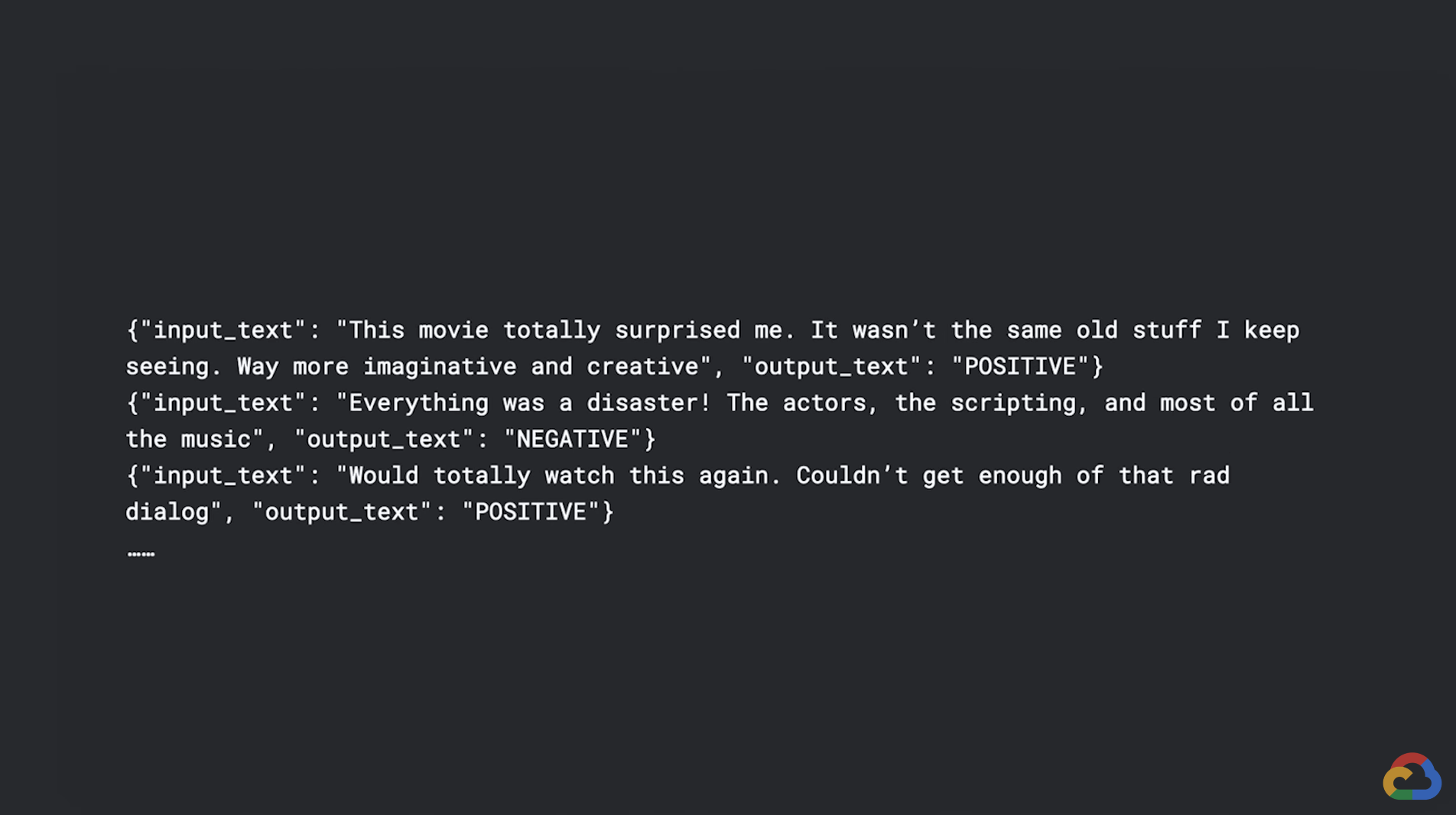
- Your training data should be structured as a supervised training dataset in a text-to-text format.
- Each record or row in the data will contain the input text. In other words, the prompt is followed by the expected output of the model.
- This means that the model can be tuned for a task that can be modeled as a text-to-text problem.
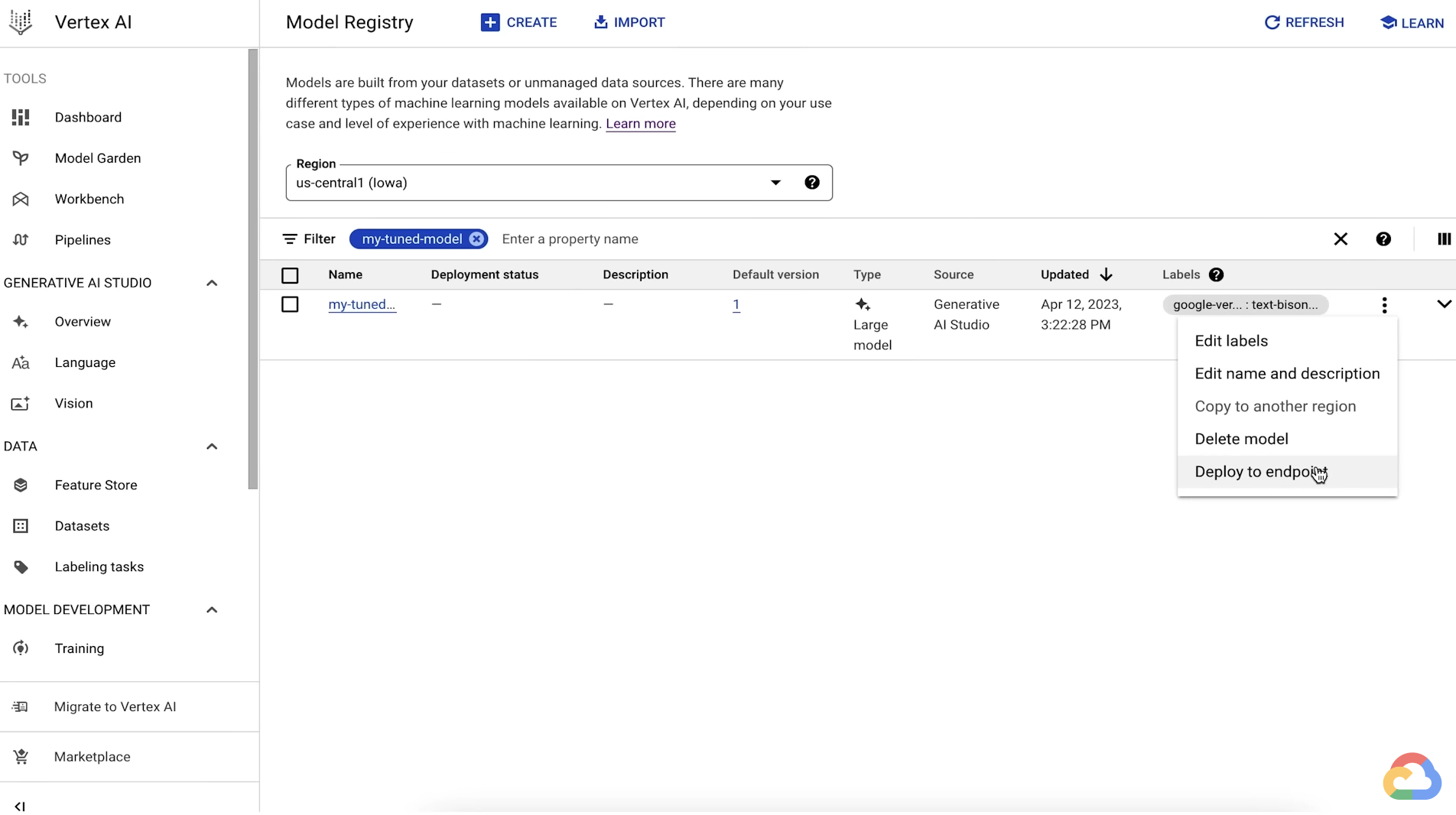
- When the tuning job completes, you'll see the tuned model in the Vertex AI Model Registry and you can deploy it to an endpoint for serving.

Course Review: Reflection Cards
https://storage.googleapis.com/cloud-training/cls-html5-courses/T-GENAISTUDIO-B/index.html#/
Introduction to Generative AI Studio: Reflection Cards
storage.googleapis.com





* 같이 읽으면 좋은 자료: https://devocean.sk.com/blog/techBoardDetail.do?ID=164779&boardType=techBlog
LLM 모델 튜닝, 하나의 GPU로 가능할까? Parameter Efficient Fine-Tuning(PEFT)을 소개합니다!
devocean.sk.com
https://www.thedatahunt.com/trend-insight/what-is-prompt#peurompeuteu-enjinieoring-vt-pain-tyuning
프롬프트 (Prompt) 란 무엇인가? - 정의, 원리, fine tuning
프롬프트 (Prompt) 란, 생성형 모델에게 어떤 행동을 해야 하는지 자연어로 설명하고 원하는 결과물을 출력할 수 있도록 하는 방식을 의미합니다. 생성 AI를 사용하는데 필요한 Prompt는 이미 프롬프
www.thedatahunt.com



