

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- nlp
- medium
- 알고리즘
- 릿코드
- slidingwindow
- Python3
- 투포인터
- gcp
- GenerativeAI
- 파이썬
- dfs
- 자연어처리
- tree
- 파이썬기초100제
- stratascratch
- heap
- 리트코드
- Python
- sql코테
- 니트코드
- 생성형AI
- 슬라이딩윈도우
- GenAI
- codeup
- 코드업
- LeetCode
- 파이썬알고리즘
- SQL
- two-pointer
- Microsoft
Archives
- Today
- Total
Tech for good
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 7. Attention Mechanism 본문
IT/Cloud
[Google Cloud Skills Boost(Qwiklabs)] Introduction to Generative AI Learning Path - 7. Attention Mechanism
Diana Kang 2023. 9. 9. 15:51https://www.youtube.com/playlist?list=PLIivdWyY5sqIlLF9JHbyiqzZbib9pFt4x
Generative AI Learning Path
https://goo.gle/LearnGenAI
www.youtube.com
Attention mechanism is behind all the transformer models and which is core to the LLM models.
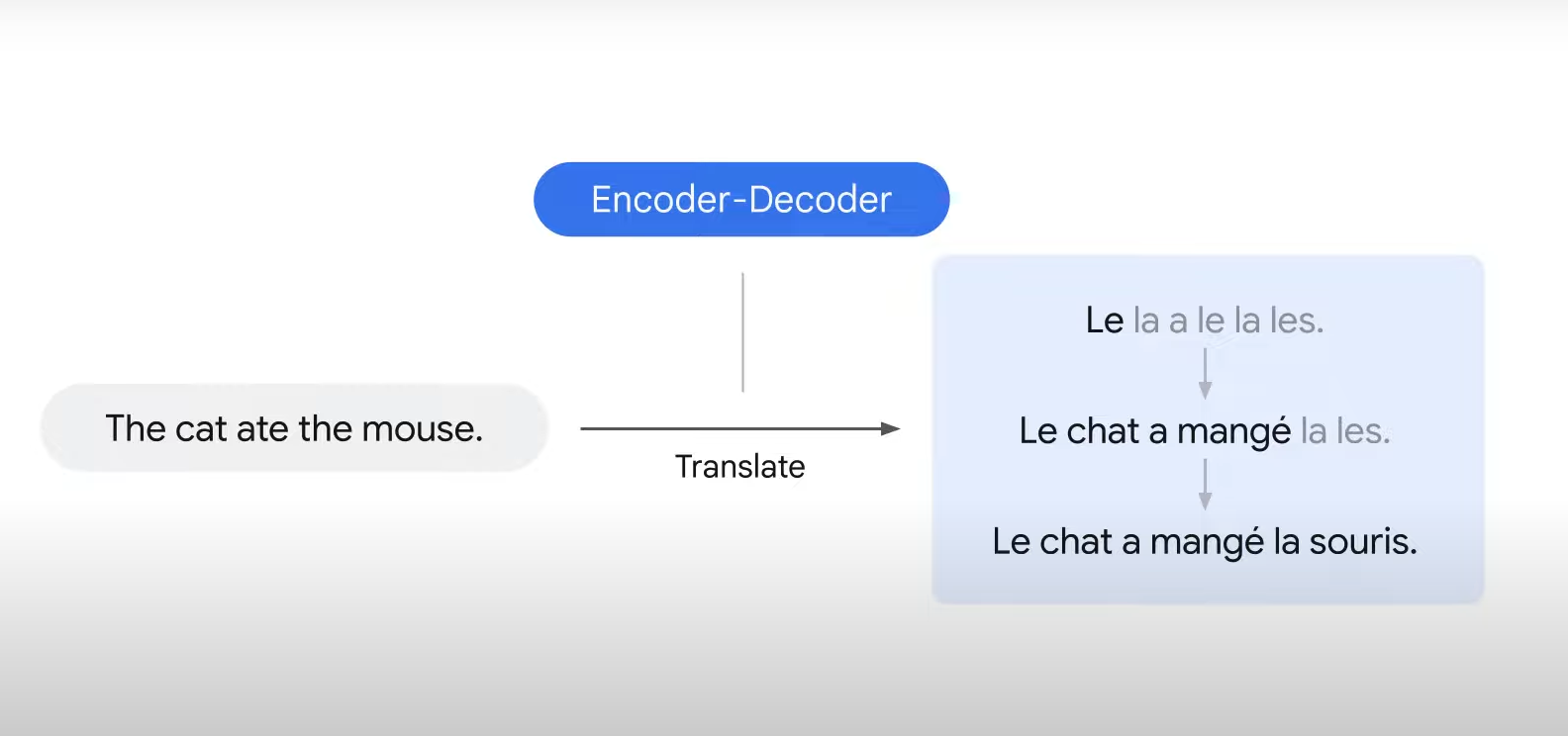
- Encoder-Decoder is a popular model that is used to translate sentences.
- The encoder-decoder takes one word at a time and translates it at each time step.

- However, sometimes the words in the source language do not align with the words in the target languages.
- ex) The first English word is black, however, in the translation, the first French word is chat which means cat in English.
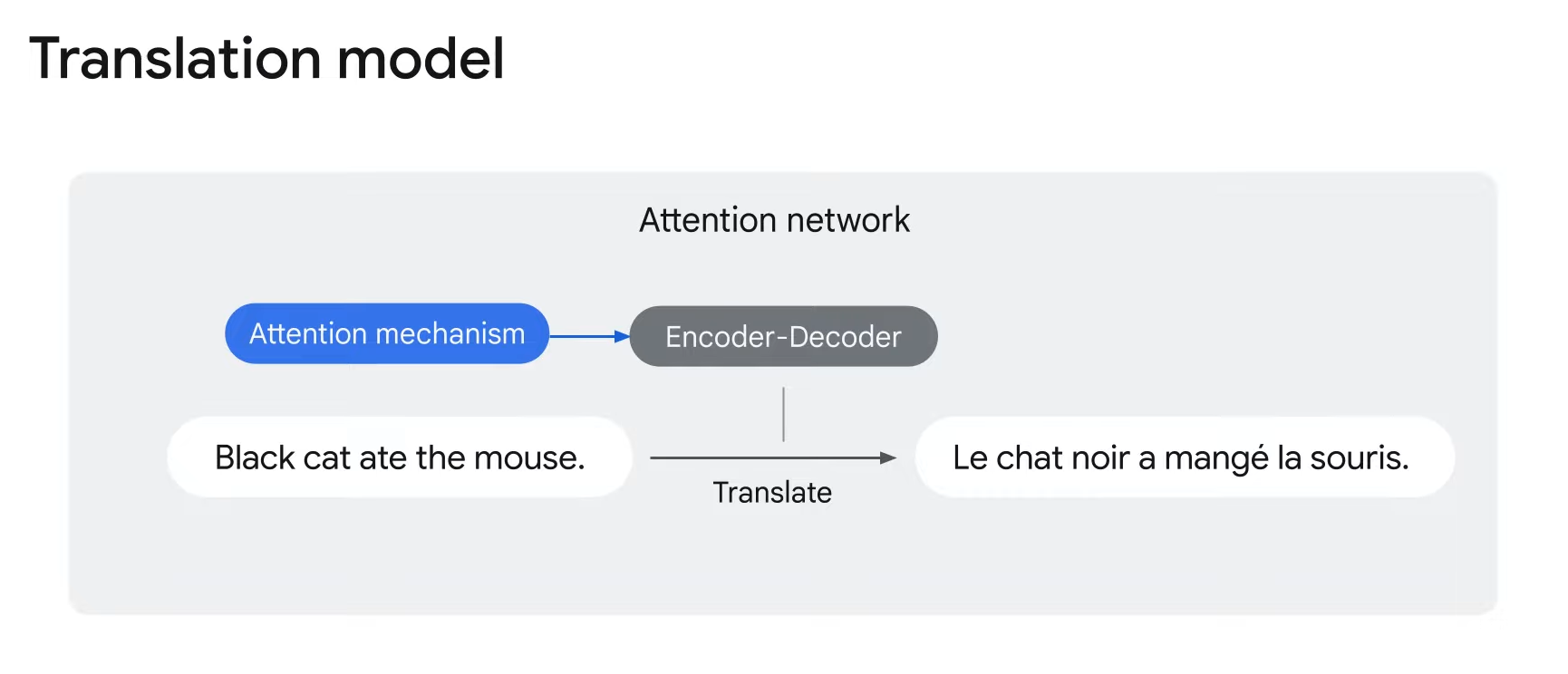
- Then how can you train a model to focus more on the word cat instead of the word black?
- To improve the translation, you can add the attention mechanism to the encoder-decoder.
- Attention mechanism is a technique that allows the neural network to focus on specific parts of an input sequence.
- This is done by assigning weights to different parts of the input sequence with the most important parts receiving the highest weights.
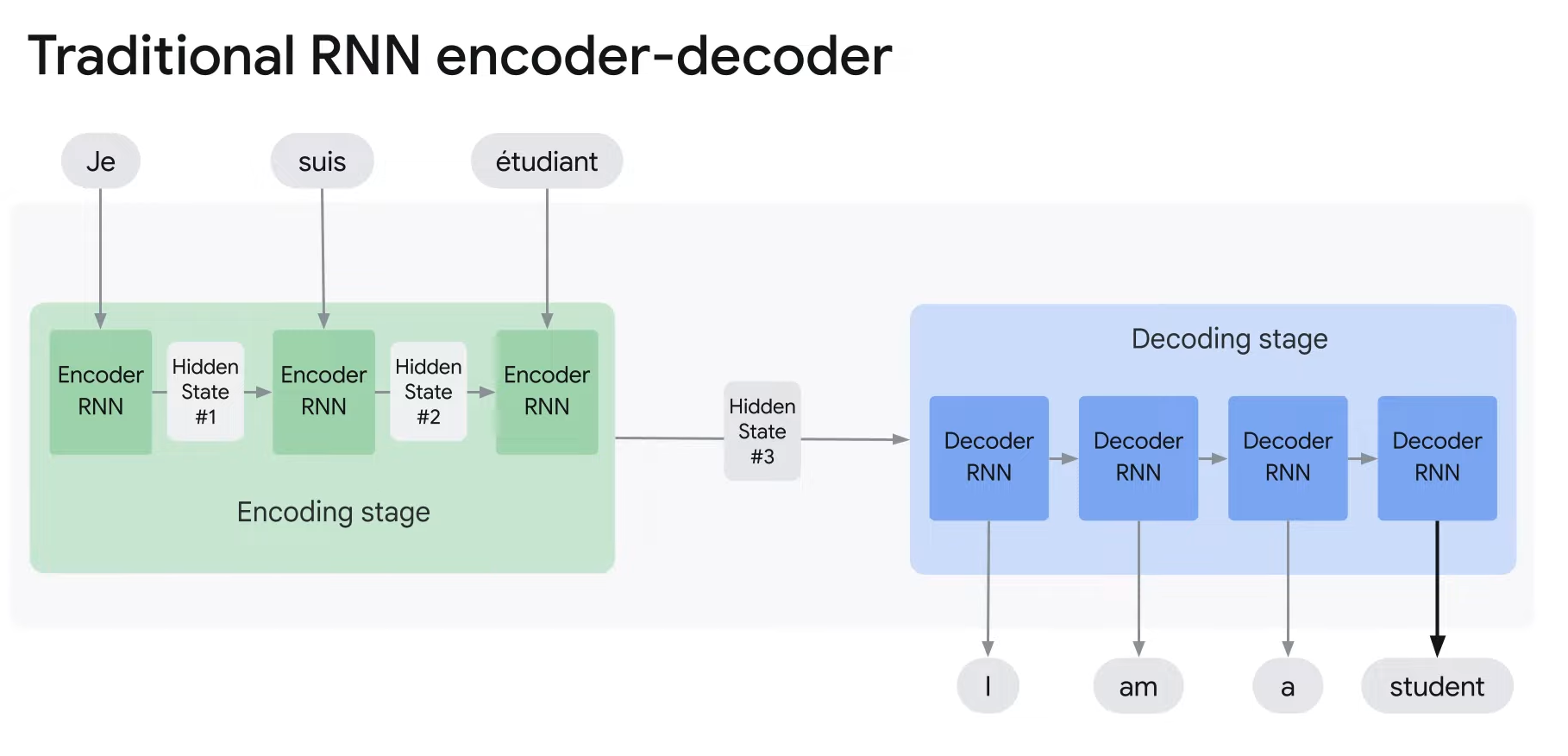
- In the traditional RNN encoder-decoder, the model takes one word at a time as input, updates the hidden state, and passes it on to the next time step.
- Only the final hidden state is passed on the decoder.
- The decoder works with the final hidden state for processing and translates it to the target language.

- An attention model differs from the traditional sequence-to-sequence model in two ways.
1. The encoder passes a lot more data to the decoder.
- So instead of just passing the final hidden state number #3 to the decoder, the encoder passes all the hidden states from each time step.
- This gives the decoder more context beyond just the final hidden state.
- The decoder uses all the hidden state information to translate the sentence.
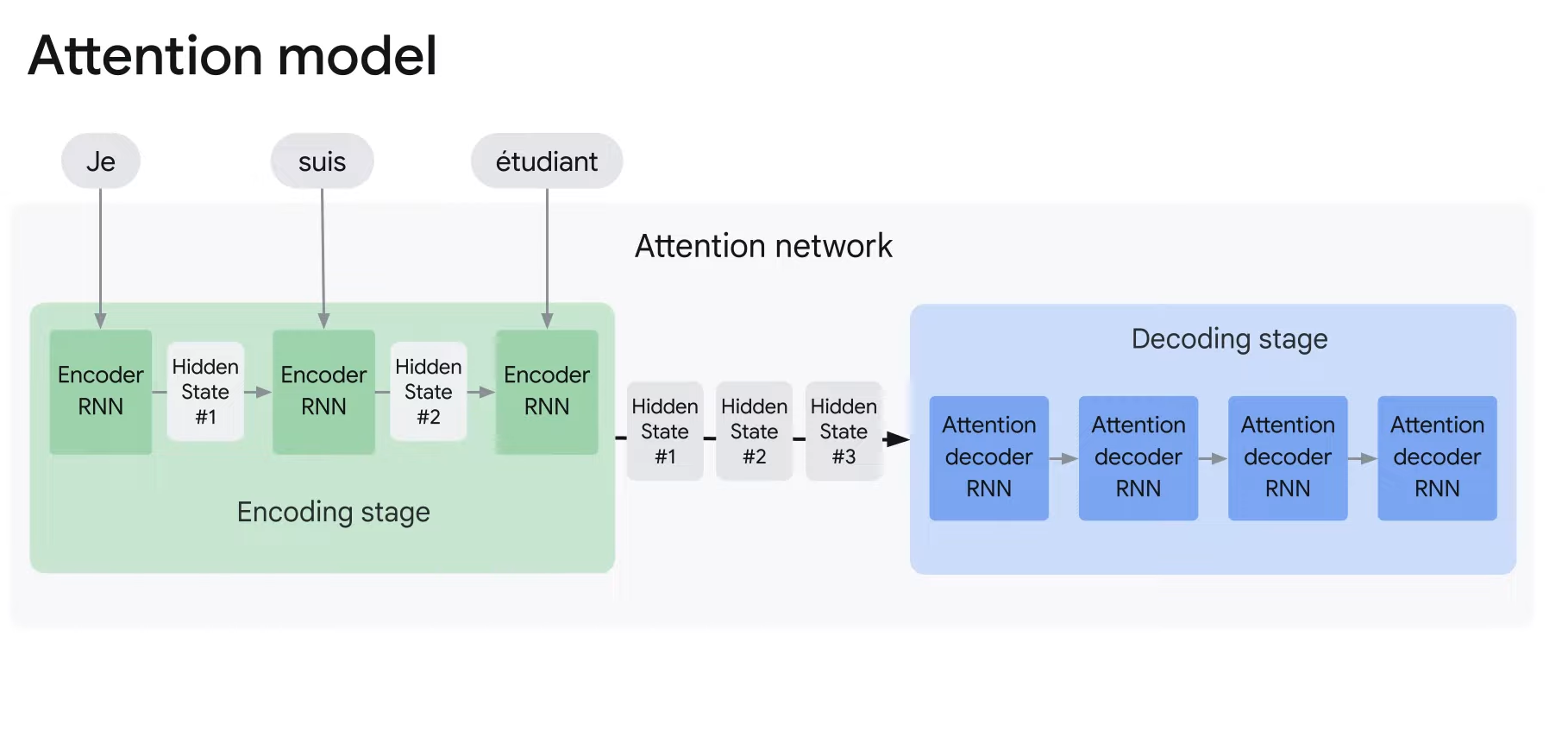
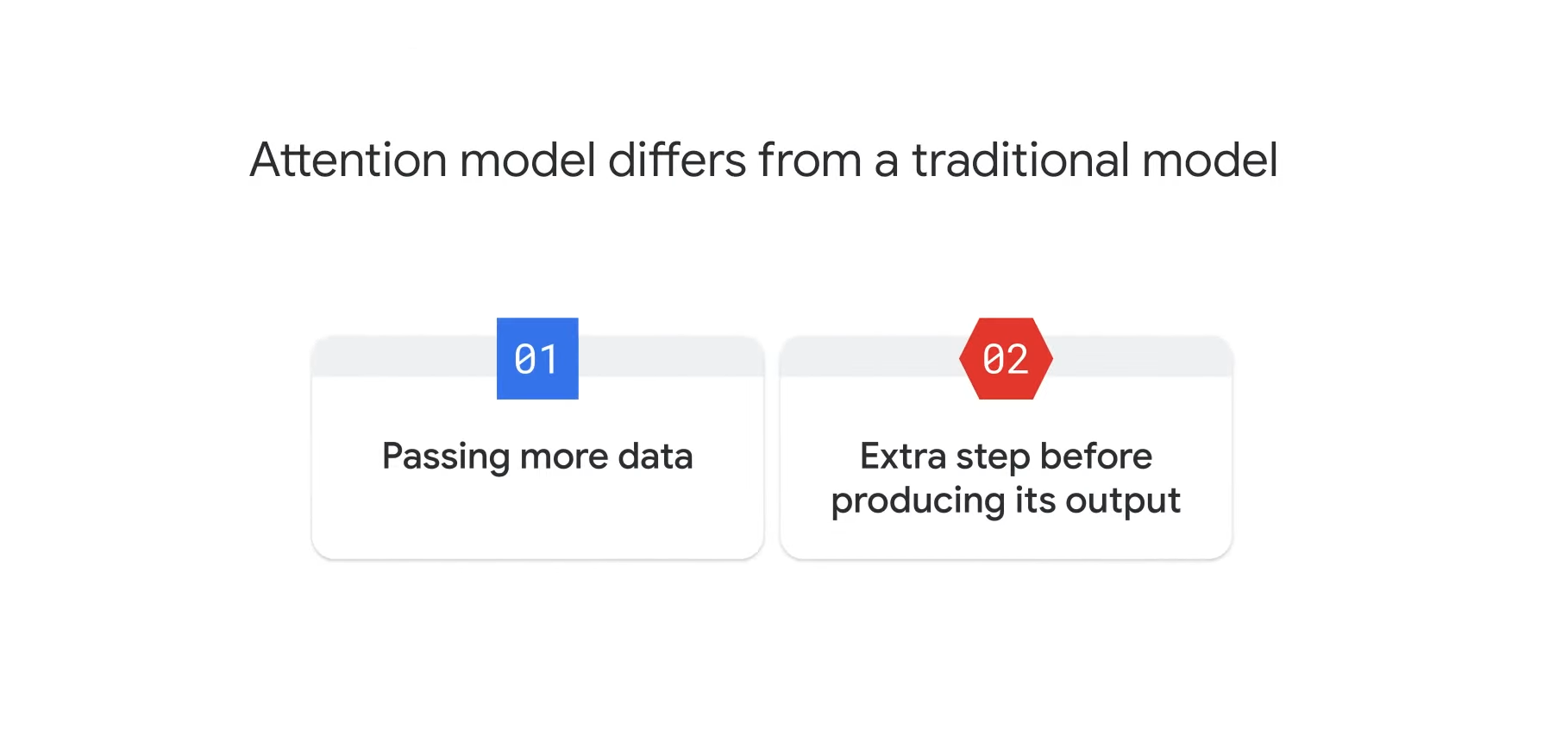
2. The attention mechanism is adding an extra step to the decoder before producing its output.
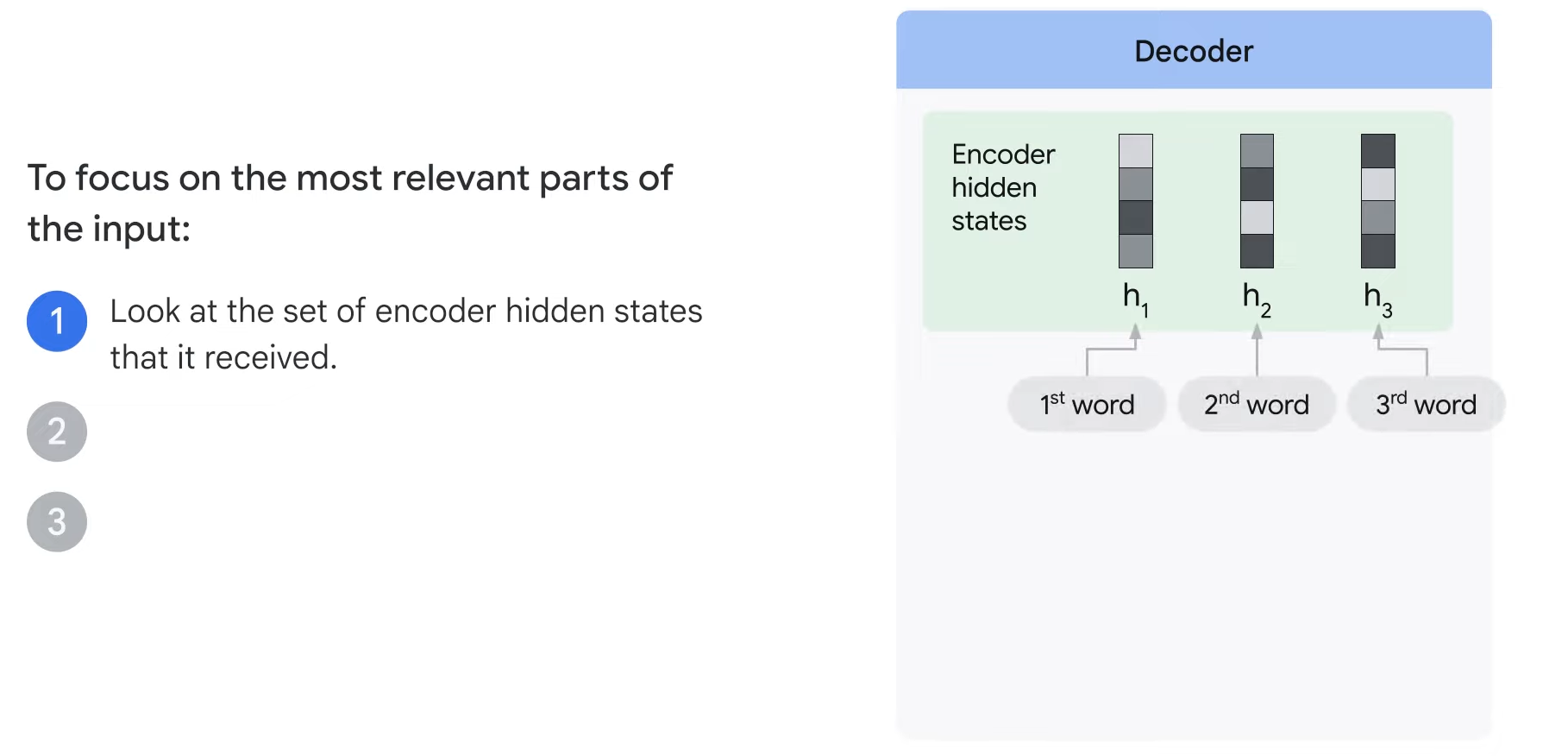
- To focus on the most relevant parts of the input, the decoder does the following:
- Step1. It looks at the set of encoder states that it has received.
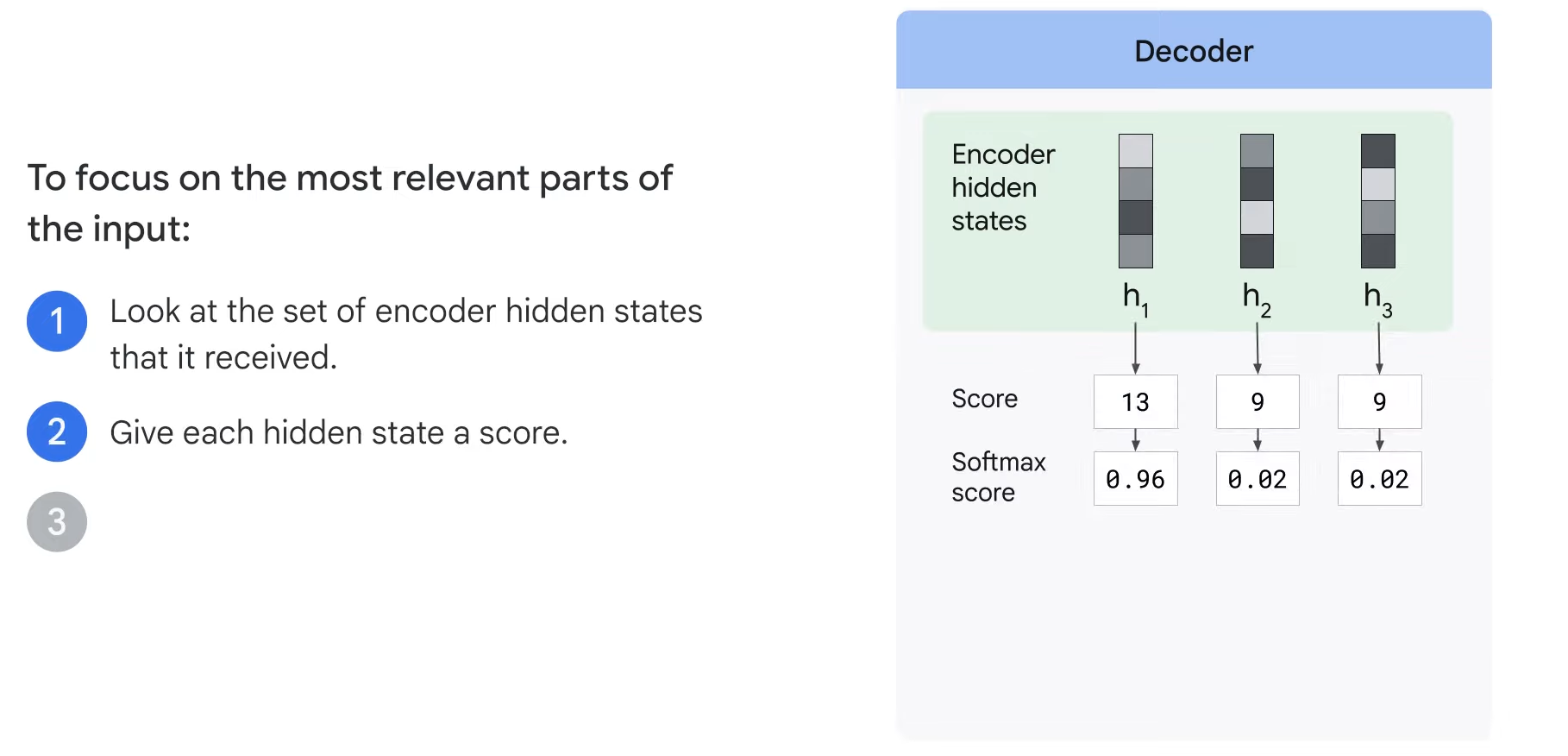
- Step2. It gives each hidden state a score.
- Step3. It multiplies each hidden state by its soft-max score.
- Thus amplifying hidden states with the highest scores(초록색) and downsizing hidden states with low scores(회색).
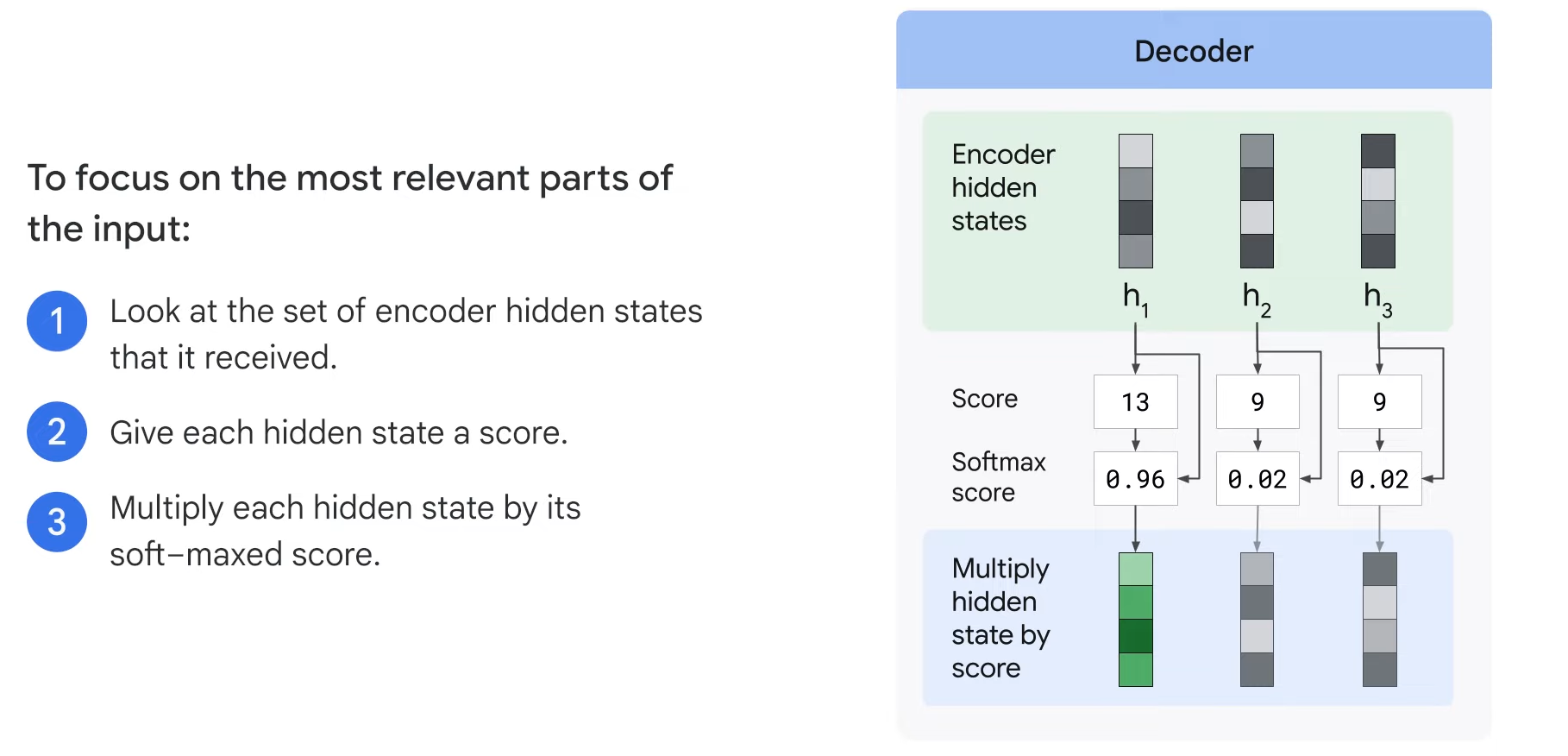
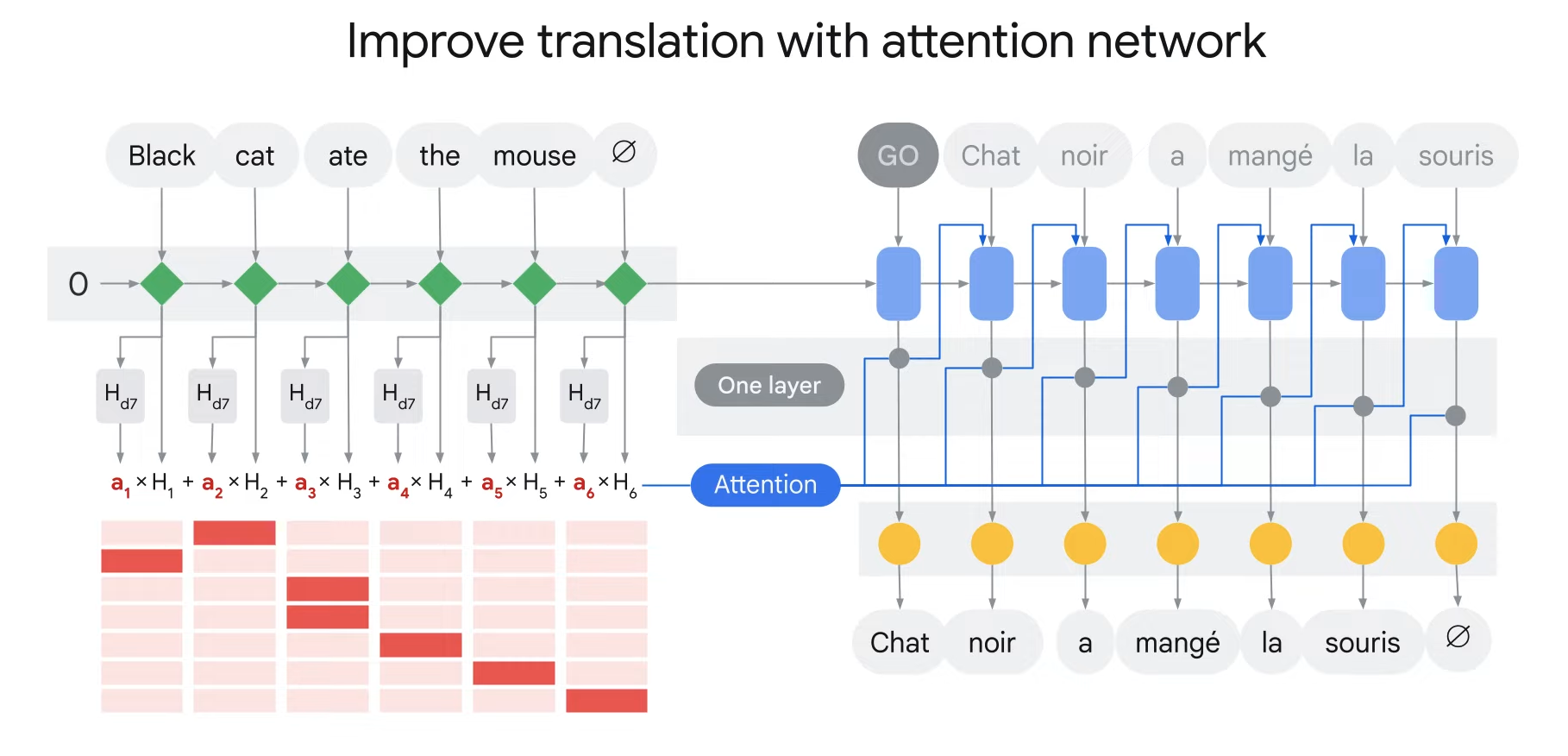
- H -> the hidden state of the encoder RNN at each time step
This is how you can use an attention mechanism to improve the performance
of a traditional encoder-decoder architecture.







'IT > Cloud' 카테고리의 다른 글
'IT/Cloud' Related Articles
more



